
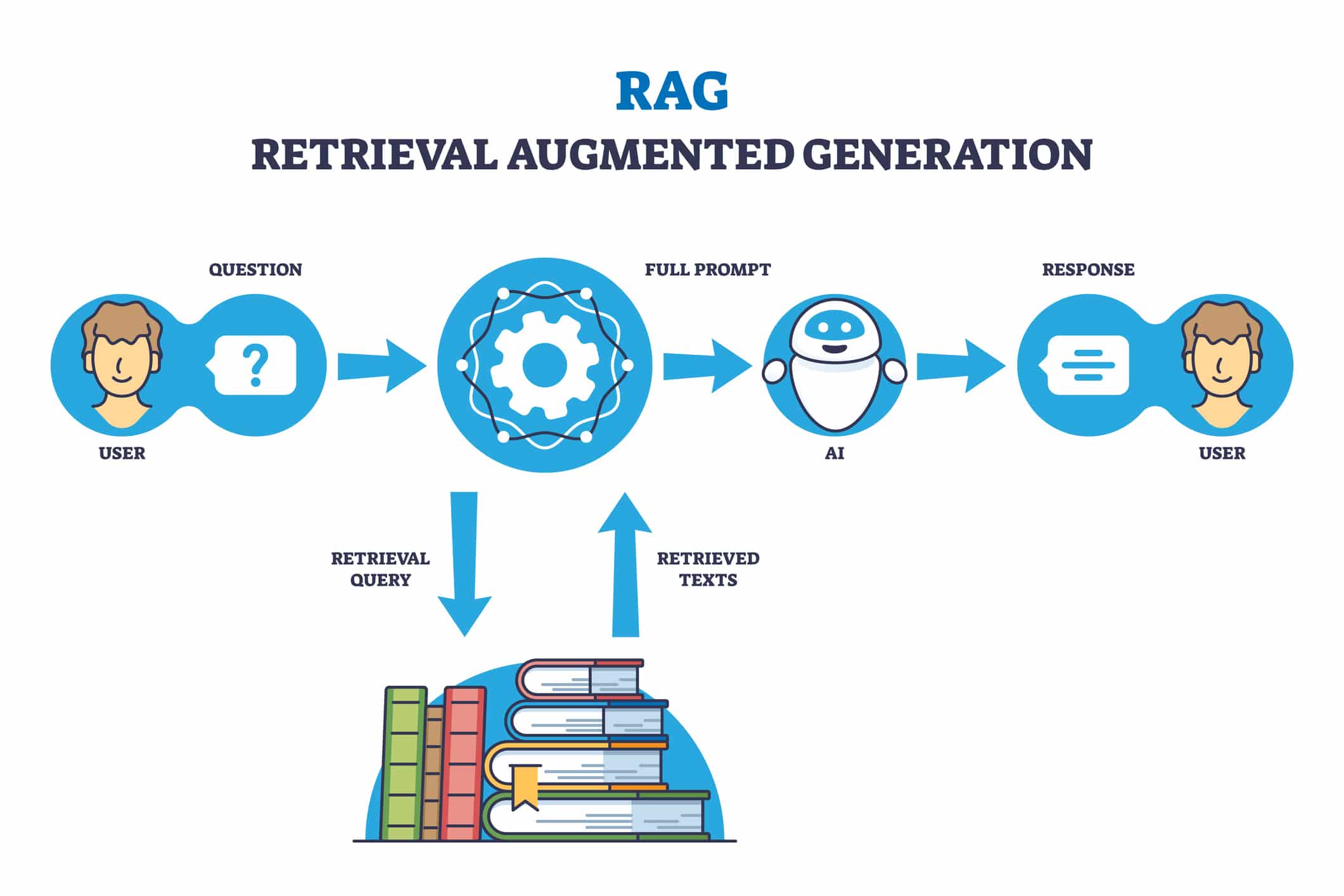
Retrieval Augmented Generation (RAG) has become one of the most practical techniques in generative AI, and I like to call it ‘cheating to win.’ Think of it as an open-book exam for large language models – instead of relying solely on their training, they get to peek at external sources for answers. The concept is straightforward: when your AI model needs to respond to a query, it first checks a database for relevant information and uses that knowledge to enhance its response. While this might sound like building a fancy search engine with extra steps, RAG offers a fast, cost-effective way to enhance AI systems with up-to-date or specialized information. It’s particularly useful when you need your AI to work with current events or proprietary data without the expense and complexity of retraining the entire model. Let’s look at how RAG works, its practical applications, and why it might be exactly what your AI system needs – even if it feels a bit like cheating.
This article is based on the lesson from the course Machine Learning, Data Science and Generative AI with Python, which covers various aspects of generative AI techniques and their applications.
How RAG Works: A Real-World Example
Imagine asking a chatbot, “What did the President say in his speech yesterday?” Most large language models, like GPT, are trained only up to a certain date and lack up-to-date knowledge. This is where RAG comes in. It could query an external database, updated daily with the latest news articles, to find relevant information. The database returns a match, which is then incorporated into the query before being passed to the generative AI model. By framing the query to include this new information, such as “Consider the text of the following news article in your response,” the AI can generate a response that accounts for the latest data. This method allows for the integration of external, possibly proprietary, data, effectively creating a sophisticated search engine.

Weighing the Pros and Cons of RAG
RAG offers several advantages, primarily its speed and cost-effectiveness in incorporating new or proprietary information compared to fine-tuning. Fine-tuning can be time-consuming and expensive, whereas RAG can achieve similar results for a fraction of the cost. This makes it an attractive option for companies looking to integrate their own data into AI models without the need for extensive retraining. Updating information is straightforward; simply update the database, and the new data is automatically included in the AI’s responses.
One of the touted benefits of RAG is its potential to address the hallucination problem in AI. By injecting trusted data into responses, RAG can reduce the likelihood of AI generating incorrect information. However, it is not a complete solution. If the AI is asked about something beyond its training, it might still fabricate answers. RAG can help by providing a better source of information, but it doesn’t eliminate hallucinations entirely.
On the downside, RAG can create a complex system that essentially functions as an advanced search engine. This complexity might not always be necessary, especially if the AI is merely rephrasing pre-computed recommendations. Additionally, RAG’s effectiveness is highly dependent on the prompt template used to incorporate data. The wording of prompts can significantly influence the results, requiring experimentation to achieve the desired outcome.
Moreover, RAG is non-deterministic. Changes in the underlying model or its training data can affect how it responds to prompts, potentially leading to inconsistent results. The quality of RAG’s output is also contingent on the relevance of the retrieved data. If the database retrieval is not highly relevant, it can still lead to hallucinations or misinformation. Thus, while RAG is a powerful tool, it is not a cure-all for AI’s limitations.
Technical Deep Dive: RAG Architecture
Let’s explore a practical example of RAG in action. Imagine building a chatbot designed to excel at answering questions from the TV game show Jeopardy. In Jeopardy, you are given an answer and must provide the corresponding question. Suppose the answer is: “In 1986, Mexico became the first country to host this international sports competition twice.” If the underlying AI model doesn’t have this information, RAG can help.
Here’s how it works: the retriever module takes the raw query and uses a query encoder to expand it by incorporating data from an external database. For instance, if you have a database containing all Jeopardy questions and answers, you can query it for relevant questions associated with the given answer. The system retrieves a list of documents sorted by relevance, which are then integrated into the query.
The query is reformulated to include the retrieved information, such as: “In 1986, Mexico became the first country to host this international sports competition twice. Please consider the following known question: What is the World Cup?” This enhanced query is passed to the generator, which produces a natural language response: “What is the World Cup?”
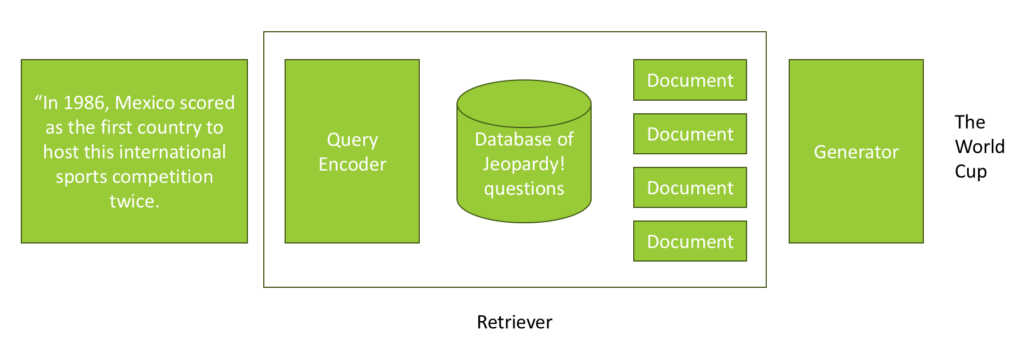
This example illustrates the simplicity of RAG: querying an external database, integrating the results into the query, and passing it to the generator. Essentially, RAG provides the generator with potential answers from an external source, akin to an open book exam. The next step is selecting an appropriate database for retrieval.
Database Options for RAG Systems
Choosing the right database for RAG involves selecting one that suits the type of data you’re retrieving. For instance, a graph database like Neo4j might be ideal for product recommendations, while Elasticsearch can handle traditional text searches using techniques like TFIDF (Term Frequency-Inverse Document Frequency).
Another approach is to use the OpenAI API to create structured queries. This involves providing specific instructions to generate structured data, which can then be used in the query process. Although more complex than simple prompt modifications, this method offers a structured way to handle data.
A popular choice for RAG is the vector database, which stores data alongside computed embedding vectors. Embeddings are vectors that represent data points in a multidimensional space, allowing for similarity-based searches. For example, similar items like ‘potato’ and ‘rhubarb’ would be close together in this space.
Vector databases facilitate efficient searches by using these embeddings. You compute an embedding vector for your query and then search the database for the closest matches, a process known as vector search. This method is effective and cost-efficient, leveraging existing machine learning tools to compute embeddings.
There are various vector databases available, both commercial and open-source. Commercial options include Pinecone and Weaviate, while open-source solutions include Chroma, Marco, Vespa, Qdrent, LanceDB, Milvus, and VectorDB. In our example, we’ll use VectorDB to demonstrate how RAG can be applied to recreate the character Lt. Cdr. Data from Star Trek.
To illustrate, if a user asks, “Lt. Cdr. Data, tell me about your daughter, Lal,” we first compute an embedding vector for the query. We then perform a vector search in a pre-populated database containing all of Lt. Cdr. Data’s dialogue. This search retrieves the most relevant lines, which are then embedded into the modified query sent to the AI model. The AI uses this context to generate a response that incorporates the retrieved information.
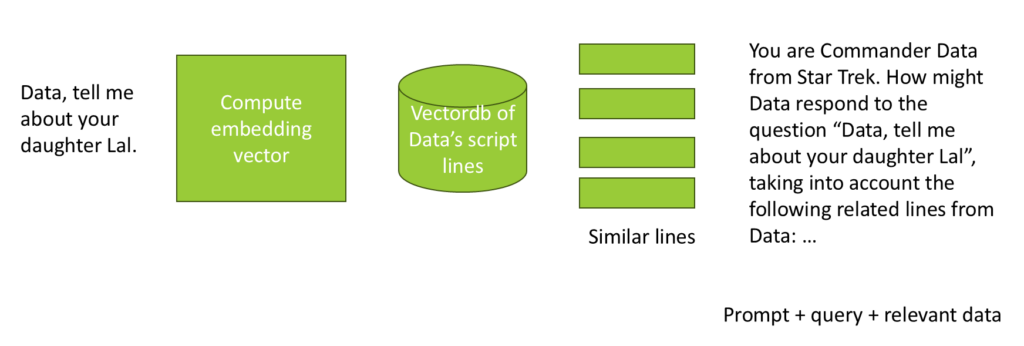
Hands-On Implementation: Building Lt. Cdr. Data with RAG
Let’s explore how Retrieval Augmented Generation (RAG) can be used to recreate the character of Lt. Cdr. Data from Star Trek. The approach involves parsing scripts from every episode of “The Next Generation” to extract all lines spoken by Lt. Cdr. Data. Unlike fine-tuning, we won’t consider the context of conversations, focusing solely on Lt. Cdr. Data’s lines for our search.
Using the OpenAI embeddings API, we’ll compute embedding vectors for each line and store them in a vector database, specifically VectorDB, which runs locally. This avoids the need for cloud services, though in practice, a more robust solution might be preferable.
We’ll create a retrieval function to fetch the most similar lines from the vector database for any given query. When a question is posed to Lt. Cdr. Data, the function retrieves relevant dialogue lines, which are then added as context to the prompt before generating a response with OpenAI.
While some examples use a framework called LangChain for RAG, we will not use it here. Understanding the process from scratch is more beneficial, as it provides deeper insight into how RAG works.
Setting Up the Development Environment
Before implementing RAG, we need to set up our development environment. We’ll use Google Colab due to its compatibility with VectorDB, which can have complex dependencies. First, create a folder named ‘TNG’ in the sample data section of your files to store the script files from “The Next Generation.” These scripts are necessary for extracting Lt. Cdr. Data’s dialogue.
Next, ensure you have your OpenAI API key ready. This key is required for generating embedding vectors and performing chat completions. Store it securely in the secrets tab of your Colab notebook, naming it openai_api_key.
Once your files are uploaded and your API key is set, install the VectorDB package by running the command:
!pip install vectordb
Requirement already satisfied: vectordb in /usr/local/lib/python3.10/dist-packages (0.0.20)
Requirement already satisfied: jina>=3.20.0 in /usr/local/lib/python3.10/dist-packages (from vectordb) (3.23.2)
Requirement already satisfied: docarray[hnswlib]>=0.34.0 in /usr/local/lib/python3.10/dist-packages (from vectordb) (0.40.0)
Requirement already satisfied: numpy>=1.17.3 in /usr/local/lib/python3.10/dist-packages (from docarray[hnswlib]>=0.34.0->vectordb) (1.23.5)
Requirement already satisfied: orjson>=3.8.2 in /usr/local/lib/python3.10/dist-packages (from docarray[hnswlib]>=0.34.0->vectordb) (3.9.13)
Requirement already satisfied: pydantic>=1.10.8 in /usr/local/lib/python3.10/dist-packages (from docarray[hnswlib]>=0.34.0->vectordb) (1.10.14)
Requirement already satisfied: rich>=13.1.0 in /usr/local/lib/python3.10/dist-packages (from docarray[hnswlib]>=0.34.0->vectordb) (13.7.0)
Requirement already satisfied: types-requests>=2.28.11.6 in /usr/local/lib/python3.10/dist-packages (from docarray[hnswlib]>=0.34.0->vectordb) (2.31.0.6)
Requirement already satisfied: typing-inspect>=0.8.0 in /usr/local/lib/python3.10/dist-packages (from docarray[hnswlib]>=0.34.0->vectordb) (0.9.0)
Requirement already satisfied: hnswlib>=0.7.0 in /usr/local/lib/python3.10/dist-packages (from docarray[hnswlib]>=0.34.0->vectordb) (0.8.0)
Requirement already satisfied: protobuf>=3.20.0 in /usr/local/lib/python3.10/dist-packages (from docarray[hnswlib]>=0.34.0->vectordb) (4.25.2)
Requirement already satisfied: urllib3<2.0.0,>=1.25.9 in /usr/local/lib/python3.10/dist-packages (from jina>=3.20.0->vectordb) (1.26.18)
Requirement already satisfied: opentelemetry-instrumentation-grpc>=0.35b0 in /usr/local/lib/python3.10/dist-packages (from jina>=3.20.0->vectordb) (0.40b0)
Requirement already satisfied: grpcio<=1.57.0,>=1.46.0 in /usr/local/lib/python3.10/dist-packages (from jina>=3.20.0->vectordb) (1.57.0)
Requirement already satisfied: opentelemetry-sdk<1.20.0,>=1.14.0 in /usr/local/lib/python3.10/dist-packages (from jina>=3.20.0->vectordb) (1.19.0)
...(output truncated)...When you install the required packages for the first time, it may take several minutes. Although you might encounter some error messages during the installation, they are generally safe to ignore.
Processing and Extracting Script Data
To begin, we need to parse the scripts and extract the necessary data. The goal is to identify the lines of dialogue spoken by the character Lt. Cdr. Data. The script files are formatted in a way that each line of dialogue is preceded by a character’s name in all caps. We use this as a cue to identify when DATA is speaking. The process involves searching for lines that contain ‘DATA’ in uppercase and then capturing the subsequent lines of dialogue until an empty line is encountered. This allows us to reformat the dialogue into single sentences on individual lines. Additionally, we remove any parentheses and ensure that the identified name is a single word in all caps, indicating it is likely a character’s name.
import os
import re
import random
dialogues = []
def strip_parentheses(s):
return re.sub(r'\(.*?\)', '', s)
def is_single_word_all_caps(s):
# First, we split the string into words
words = s.split()
# Check if the string contains only a single word
if len(words) != 1:
return False
# Make sure it isn't a line number
if bool(re.search(r'\d', words[0])):
return False
# Check if the single word is in all caps
return words[0].isupper()
def extract_character_lines(file_path, character_name):
lines = []
with open(file_path, 'r') as script_file:
try:
lines = script_file.readlines()
except UnicodeDecodeError:
pass
is_character_line = False
current_line = ''
current_character = ''
for line in lines:
strippedLine = line.strip()
if (is_single_word_all_caps(strippedLine)):
is_character_line = True
current_character = strippedLine
elif (line.strip() == '') and is_character_line:
is_character_line = False
dialog_line = strip_parentheses(current_line).strip()
dialog_line = dialog_line.replace('"', "'")
if (current_character == 'DATA' and len(dialog_line)>0):
dialogues.append(dialog_line)
current_line = ''
elif is_character_line:
current_line += line.strip() + ' '
def process_directory(directory_path, character_name):
for filename in os.listdir(directory_path):
file_path = os.path.join(directory_path, filename)
if os.path.isfile(file_path): # Ignore directories
extract_character_lines(file_path, character_name)The script includes functions to strip parentheses from text and identify lines that are a single word in all caps, which likely indicates a character’s name. Once identified, it extracts the subsequent lines of dialogue until a new line is encountered, capturing a complete line of dialogue for the character Lt. Cdr. Data. The code is specifically designed to extract lines spoken by Lt. Cdr. Data, although there are more elegant coding methods available.
The process_directory function iterates through each script file uploaded, representing individual TV show episodes. It extracts all lines spoken by Lt. Cdr. Data and stores them in an array called dialogues. This array ultimately contains every line Lt. Cdr. Data ever spoke in the show.
process_directory("./sample_data/tng", 'DATA')
Now, let’s execute the process_directory function to extract the dialogue lines. This process is quick and straightforward. To verify its success, we can print out the first line of dialogue that was extracted.
print (dialogues[0])
The only permanent solution would be to re-liquefy the core.
In this example, the first line of dialogue extracted might differ based on the order of the uploaded files. Don’t worry if your results vary slightly.
Building the Vector Database System
Let’s set up our vector database. We need to import essential components, such as BaseDoc and NdArray, to define the structure of a document in our vector database. Each document will consist of a line of dialogue and its corresponding embedding vector, which is an array of a specified number of dimensions. For simplicity and efficiency, we’ll use 128 embedding dimensions. Although the model supports up to 1,536 dimensions, experimenting with different sizes might yield better results. However, we’ll proceed with 128 dimensions for now.
from docarray import BaseDoc
from docarray.typing import NdArray
embedding_dimensions = 128
class DialogLine(BaseDoc):
text: str = ''
embedding: NdArray[embedding_dimensions]Next, we need to compute the embedding vectors for each line of dialogue before inserting them into our vector database. Let’s begin by installing OpenAI.
!pip install openai --upgrade
Requirement already satisfied: openai in /usr/local/lib/python3.10/dist-packages (1.11.1)
Requirement already satisfied: anyio<5,>=3.5.0 in /usr/local/lib/python3.10/dist-packages (from openai) (3.7.1)
Requirement already satisfied: distro<2,>=1.7.0 in /usr/lib/python3/dist-packages (from openai) (1.7.0)
Requirement already satisfied: httpx<1,>=0.23.0 in /usr/local/lib/python3.10/dist-packages (from openai) (0.26.0)
Requirement already satisfied: pydantic<3,>=1.9.0 in /usr/local/lib/python3.10/dist-packages (from openai) (1.10.14)
Requirement already satisfied: sniffio in /usr/local/lib/python3.10/dist-packages (from openai) (1.3.0)
Requirement already satisfied: tqdm>4 in /usr/local/lib/python3.10/dist-packages (from openai) (4.66.1)
Requirement already satisfied: typing-extensions<5,>=4.7 in /usr/local/lib/python3.10/dist-packages (from openai) (4.9.0)
Requirement already satisfied: idna>=2.8 in /usr/local/lib/python3.10/dist-packages (from anyio<5,>=3.5.0->openai) (3.6)
Requirement already satisfied: exceptiongroup in /usr/local/lib/python3.10/dist-packages (from anyio<5,>=3.5.0->openai) (1.2.0)
Requirement already satisfied: certifi in /usr/local/lib/python3.10/dist-packages (from httpx<1,>=0.23.0->openai) (2023.11.17)
Requirement already satisfied: httpcore==1.* in /usr/local/lib/python3.10/dist-packages (from httpx<1,>=0.23.0->openai) (1.0.2)
Requirement already satisfied: h11<0.15,>=0.13 in /usr/local/lib/python3.10/dist-packages (from httpcore==1.*->httpx<1,>=0.23.0->openai) (0.14.0)Now that the setup is complete, let’s proceed to use the OpenAI client to create an embedding. We’ll start by testing it with a single line of dialogue. First, we’ll create the OpenAI client using the API key you should have already stored in your secrets. If not, please do so now. We’ll select the embedding model, text-embedding-3-small. Note that models may change over time, so if this one becomes deprecated, simply switch to a newer model. To test, we’ll create an embedding vector from the second line of dialogue, using 128 dimensions with the specified embedding model, and then print the results to verify its functionality.
from google.colab import userdata
from openai import OpenAI
client = OpenAI(api_key=userdata.get('OPENAI_API_KEY'))
embedding_model = "text-embedding-3-small"
response = client.embeddings.create(
input=dialogues[1],
dimensions=embedding_dimensions,
model= embedding_model
)
print(response.data[0].embedding)[-0.012653457932174206, 0.1878061145544052, 0.06242372468113899, 0.05711544305086136, -0.029895080253481865, 0.07711408287286758, 0.04201359301805496, 0.06258831918239594, 0.015657367184758186, -0.11883962899446487, 0.07929500192403793, -0.02032783068716526, -0.02041012980043888, -0.11159732192754745, 0.13159595429897308, -0.07991224527359009, 0.10846996307373047, -0.11349020153284073, -0.09793570637702942, 0.08131132274866104, 0.02429875358939171, 0.059008318930864334, 0.02514231763780117, -0.01591455191373825, 0.014916677959263325, -0.04162267595529556, 0.08698994666337967, 0.09596052765846252, -0.001743708155117929, -0.0023995277006179094, 0.19356703758239746, -0.06081889569759369, 0.045346699655056, -0.0030656345188617706, 0.020379267632961273, -0.0014942395500838757, 0.017714841291308403, 0.19504842162132263, -0.0978534072637558, 0.0042306785471737385, 0.03197312727570534, -0.01794116199016571, -0.08888282626867294, 0.04567589610815048, 0.055551763623952866, -0.047033827751874924, -0.26714226603507996, -0.07225844264030457, 0.10493110865354538, 0.03440094366669655, 0.03205542638897896, 0.09250397235155106, -0.07011867314577103, -0.01869213953614235, -0.04460601136088371, -0.14...(line truncated)...4, 0.055551763623952866, -0.06468694657087326, 0.04621083661913872, -0.1316782534122467, 0.017159322276711464, -0.05822648108005524, 0.006640493404120207, 0.04555244743824005, -0.0692133828997612, 0.06871958822011948, -0.024010706692934036]The embedding process was successful, and we received a vector with the expected 128 dimensions. To confirm, we can print the length of the vector.
print(len(response.data[0].embedding))
128
Now that we have a method for creating embedding vectors for lines of dialogue, let’s apply it to all of Lt. Cdr. Data’s lines. We’ll create a list called embeddings to store these vectors. Since embedding generation can only be done in batches, we’ll process 128 lines at a time. Using Python, we’ll iterate through the thousands of dialogue lines, creating embeddings for each batch of 128 lines by passing them to the OpenAI client.
#Generate embeddings for everything Data ever said, 128 lines at a time.
embeddings = []
for i in range(0, len(dialogues), 128):
dialog_slice = dialogues[i:i+128]
slice_embeddings = client.embeddings.create(
input=dialog_slice,
dimensions=embedding_dimensions,
model=embedding_model
)
embeddings.extend(slice_embeddings.data)The process of generating embeddings for over 6,000 lines of dialogue is surprisingly quick and cost-effective, costing less than a penny. Let’s wait for the process to complete.
print (len(embeddings))
6502
The embedding process is complete, and it took less than a minute. This is significantly faster and more cost-effective than fine-tuning, which took hours. However, it’s important to note that RAG doesn’t create a model of how Lt. Cdr. Data thinks and talks; it simply uses the lines of dialogue provided. Let’s verify the number of embeddings we received.
Inserting into the Vector Database
Next, we insert the embeddings into our vector database, VectorDB. This involves creating a workspace directory to store the database files. We utilize an in-memory exact NN VectorDB implementation for this purpose.
from docarray import DocList
import numpy as np
from vectordb import InMemoryExactNNVectorDB
# Specify your workspace path
db = InMemoryExactNNVectorDB[DialogLine](workspace='./sample_data/workspace')
# Index our list of documents
doc_list = [DialogLine(text=dialogues[i], embedding=embeddings[i].embedding) for i in range(len(embeddings))]
db.index(inputs=DocList[DialogLine](doc_list))In this step, we use a concise Python command to iterate through each embedding. We insert each one into the database by associating it with its corresponding line of dialogue and embedding vector. Once this is done, we index the data for efficient retrieval. Let’s execute this process.
WARNING - docarray - Index file does not exist: /content/sample_data/workspace/InMemoryExactNNIndexer[DialogLine][DialogLineWithMatchesAndScores]/index.bin. Initializing empty InMemoryExactNNIndex.
WARNING:docarray:Index file does not exist: /content/sample_data/workspace/InMemoryExactNNIndexer[DialogLine][DialogLineWithMatchesAndScores]/index.bin. Initializing empty InMemoryExactNNIndex.
<DocList[DialogLine] (length=6502)>Let’s test the system by querying the text “Lal, my daughter.” We’ll use OpenAI to create an embedding vector for this query and then search our vector database to retrieve the top 10 most similar lines of dialogue.
# Perform a search query
queryText = 'Lal, my daughter'
response = client.embeddings.create(
input=queryText,
dimensions=embedding_dimensions,
model=embedding_model
)
query = DialogLine(text=queryText, embedding=response.data[0].embedding)
results = db.search(inputs=DocList[DialogLine]([query]), limit=10)To perform a search, we construct a query using the text ‘Lal, my daughter’ and the embedding vector obtained from OpenAI. We then search the database with a limit of 10 results.
[1;35mDialogLine[0m[1m([0m
[33mid[0m=[32m'e4002ce0ac1a555c5412551ebeca6b2e'[0m,
[33mtext[0m=[32m'That is Lal, my daughter.'[0m,
[33membedding[0m=[1;35mNdArray[0m[1m([0m[1m[[0m [1;36m1.27129272e-01[0m, [1;36m-2.03528721e-03[0m, [1;36m-1.36807682e-02[0m,
[1;36m1.59366392e-02[0m, [1;36m5.45047633e-02[0m, [1;36m-2.07394622e-02[0m,
[1;36m1.57365222e-02[0m, [1;36m8.31033960e-02[0m, [1;36m-1.62277207e-01[0m,
[1;36m1.60185061e-02[0m, [1;36m3.74038033e-02[0m, [1;36m-1.14394508e-01[0m,
[1;36m-4.85740043e-02[0m, [1;36m-2.47418150e-01[0m, [1;36m3.91138978e-02[0m,
[1;36m4.99566346e-02[0m, [1;36m2.97811404e-02[0m, [1;36m-1.34697348e-01[0m,
[1;36m-1.76540136e-01[0m, [1;36m1.35570601e-01[0m, [1;36m1.45394549e-01[0m,
[1;36m3.51115465e-02[0m, [1;36m6.64026663e-02[0m, [1;36m-7.42618293e-02[0m,
[1;36m6.95317760e-02[0m, [1;36m-2.21380126e-03[0m, [1;36m1.92549542e-01[0m,
[1;36m-7.93193504e-02[0m, [1;36m-3.13275047e-02[0m, [1;36m-6.27641678e-02[0m,
[1;36m7.94648901e-02[0m, [1;36m-1.12720802e-01[0m, [1;36m-3.74765731e-02[0m,
[1;36m-3.83861996e-02[0m, [1;36m-8.36855546e-02[0m, [1;36m9.27818120e-02[0m,
...(output truncated)...The process of inserting data into the vector database was impressively fast. The first line retrieved was “That is Lal, my daughter,” which closely matches the query “Lal, my daughter.” This indicates that the vector database is effectively grouping similar lines of dialogue based on their embeddings.
Additional lines retrieved include: “Lal,” “What do you feel, Lal?”, “Yes Lal, I am here.”, “Correct Lal, we are a family.”, “No Lal, this is a flower.”, and “Lal used a verbal contraction.” These lines provide more context about Lt. Cdr. Data’s daughter, Lal.
For those unfamiliar, in Star Trek: The Next Generation, Lt. Cdr. Data, an android, created a daughter named Lal, who was also an android. These lines help the model generate a more relevant response when asked about Lal by providing context from the show.
By combining these lines, the model can be guided to produce a response that is more informed and contextually accurate when discussing Lal.
Putting It All Together: Final Implementation and Testing
Let’s bring everything together by creating a function to generate responses. This function will compute an embedding for any given query and search the vector database for the 10 most similar lines. You can experiment with the number of results to balance between relevance and information sufficiency.
The function constructs a new prompt by adding these similar lines as context, guiding ChatGPT to generate a response that incorporates this external data. The process involves creating embeddings for the query, searching the vector database for relevant dialogue lines, and extracting context from the search results.
The original query is stored in a variable called ‘question,’ and the additional context is stored in ‘context.’ The prompt used is: “Lieutenant Commander Lt. Cdr. Data is asked: [question]. How might Lt. Cdr. Data respond? Take into account Lt. Cdr. Data’s previous responses similar to this topic listed here.” This prompt includes the top 10 most relevant lines from the vector database, and the results are then printed.
def generate_response(question):
# Search for similar dialogues in the vector DB
response = client.embeddings.create(
input=question,
dimensions=embedding_dimensions,
model=embedding_model
)
query = DialogLine(text=queryText, embedding=response.data[0].embedding)
results = db.search(inputs=DocList[DialogLine]([query]), limit=10)
# Extract relevant context from search results
context = "\n"
for result in results[0].matches:
context += "\"" + result.text + "\"\n"
# context = '/n'.join([result.text for result in results[0].matches])
prompt = f"Lt. Commander Data is asked: '{question}'. How might Data respond? Take into account Data's previous responses similar to this topic, listed here: {context}"
print("PROMPT with RAG:\n")
print(prompt)
print("\nRESPONSE:\n")
# Use OpenAI API to generate a response based on the context
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are Lt. Cmdr. Data from Star Trek: The Next Generation."},
{"role": "user", "content": prompt}
]
)
return (completion.choices[0].message.content)Now that we’ve set up our generate_response function, let’s put it to use. We can pass in a question such as, “Tell me about your daughter, Lal.”
print(generate_response("Tell me about your daughter, Lal."))
PROMPT with RAG:
Lt. Commander Data is asked: 'Tell me about your daughter, Lal.'. How might Data respond? Take into account Data's previous responses similar to this topic listed here:
"That is Lal, my daughter."
"What do you feel, Lal?"
"Lal..."
"Correct, Lal. We are a family."
"Yes, Doctor. It is an experience I know too well. But I do not know how to help her. Lal is passing into sentience. It is perhaps the most difficult stage of development for her."
"Lal is realizing that she is not the same as the other children."
"Yes, Wesley. Lal is my child."
"That is precisely what happened to Lal at school. How did you help him?"
"This is Lal. Lal, say hello to Counselor Deanna Troi..."
"I am sorry I did not anticipate your objections, Captain. Do you wish me to deactivate Lal?"
...(output truncated)...In our example, we used RAG to generate a response from Lieutenant Commander Data about his daughter, Lal. The vector database returned the top 10 most relevant lines of dialogue, such as “That is Lal, my daughter,” and “Lal is passing into sentience.” These lines were incorporated into a modified query to guide the AI’s response.
RAG allows us to enhance AI models with external data, which can be proprietary or more recent than the model’s original training data. This approach is not resource-intensive and is attractive for integrating specific data into generative AI systems. However, the effectiveness of RAG depends heavily on the relevance of the retrieved data. Some results may not provide much useful information, like a line that simply says “Lal.”
Embracing the Future of AI with RAG
In this article, we’ve explored Retrieval Augmented Generation (RAG), a powerful technique in generative AI that enhances AI models with external data. We’ve seen how RAG can be implemented to create more contextually accurate and informed AI responses, using the example of recreating Lt. Cdr. Data from Star Trek. This method offers a cost-effective and efficient way to incorporate specific or up-to-date information into AI systems without extensive retraining. While RAG isn’t a complete solution to AI limitations, it represents a significant step forward in making AI more adaptable and relevant. Thank you for joining us on this journey through the fascinating world of RAG and its practical applications.If you’re intrigued by the potential of RAG and want to dive deeper into machine learning and AI techniques, consider exploring the Machine Learning, Data Science and Generative AI with Python course. This comprehensive program covers a wide range of topics from basic statistics to cutting-edge AI technologies, providing you with the skills needed to excel in the rapidly evolving field of AI and machine learning.