We recently ran a survey to figure out which social media platforms we should focus on. I’ll be honest – we’re not huge fans of social media, and don’t want to spend more time out there than we have to.
It seems a lot of you are in the same boat! The #1 platform you say you check regularly isn’t X, Facebook, Instagram, or TikTok – It’s LinkedIn!
Well that’s a a relief, as LinkedIn is probably the least toxic platform that’s still around – and it’s one that I’ve been active on anyhow.
You’ll find my slightly snarky takes on the latest developments in AI, machine learning, data engineering, and system design there, including some objective looks at the hype surrounding generative AI. If you’ve taken my courses, you know I value working backwards and simplicity when designing systems, and a lot of today’s trends are quite the opposite. Unlike most people on LinkedIn, I have nothing to lose by speaking the truth – so I hope you’ll give me a follow to balance out some of the “influencers” there.
We’ve also got a company page for Sundog Education on LinkedIn, where you’ll find more of a focus on educational resources, and a more professional tone:
In either case, I promise you the ideas and content I’m sharing on LinkedIn is from me personally – not from AI or an assistant. Give us a follow, and be sure to share things you like!
Large Language Models (LLMs) are impressive on their own, but they become truly powerful when equipped with external tools and capabilities. This concept, known as LLM agents, allows AI models to break out of their standard limitations by accessing external utilities, services, and data sources. While the idea might sound complex, it’s built around a straightforward principle: giving your LLM discretion to choose and use specific tools for specific purposes. Each tool comes with its own instructions, letting the model decide when and how to use them. For example, when faced with a mathematical problem, the LLM can recognize its limitations and delegate the computation to a specialized calculator tool. This approach isn’t limited to calculations – agents can search the web, access databases, run code, or interact with any external service you configure. Let’s explore how these agents work and see how to build one from scratch.
LLM agents are a hot topic in AI development. These agents are built around the concept of equipping Large Language Models (LLMs) with tools and functions, allowing them to access external utilities, services, and data. This capability enables LLMs to extend beyond their inherent limitations. For instance, Retrieval-Augmented Generation (RAG) is a form of LLM agent, as it provides access to external data stores like vector databases.
The core idea is to give the LLM discretion in choosing which tools to use for specific tasks. Each tool comes with a prompt indicating its purpose. For example, if the LLM encounters a math problem, it can delegate the task to a specialized tool designed for mathematical computations. This approach allows the LLM to utilize various tools to provide more accurate and comprehensive responses.
NVIDIA’s Agent Architecture: A Conceptual Framework
NVIDIA describes LLM agents through a conceptual framework that, while abstract, provides a foundational understanding. At its core, the LLM functions as the agent, equipped with access to various types of memory: short-term, long-term, and sensory. Short-term memory might include the history of a chat session, while long-term memory could involve external data stores, such as a database containing all dialogues of a character like Commander Data.
The planning module guides the LLM in breaking down complex queries into manageable sub-questions. This involves using prompts associated with each tool, as well as a system prompt that dictates the agent’s overall behavior. The user request initiates the process, with the agent core accessing memory and the planning module directing the query into tool-specific actions. The tools core comprises the individual tools available to the agent, which can interact with external services, perform computations, or execute custom functions. This framework outlines NVIDIA’s high-level conceptualization of LLM agents.
Practical Implementation of LLM Agents
In practice, implementing LLM agents involves using tools as functions provided through the tools API in OpenAI and similar platforms. These tools are guided by prompts that instruct the LLM on their usage. For instance, a tool designed for calculations might have a prompt indicating its utility for solving math problems. When a math problem arises, the LLM can delegate it to this tool.
These tools are versatile, capable of accessing external information, performing web searches, utilizing retrievers in a Retrieval-Augmented Generation (RAG) system, executing Python code, or interacting with external services. This capability effectively extends LLMs into real-world applications, enabling them to perform a wide range of tasks.
Advanced Concepts: Agent Swarms and Specialization
Expanding on the concept of LLM agents, we introduce the idea of a swarm of agents. This involves multiple agents, each specialized for different tasks. For example, in a software development system, you might have agents mimicking roles such as a game designer, an art generator, a code writer, and a test case developer. Overseeing these could be an agent simulating a Chief Technical Officer or Chief Executive Officer, strategizing the development process.
These swarms of agents collaborate to achieve a larger goal. This concept is similar to Devon AI, with ChatDev being the first implementation in China. There’s a paper and an OpenDevon package available for further exploration.
While we won’t delve into swarms here, we’ll focus on creating a specialized agent. We’ll develop an agent modeled after Lt. Cdr. Data, equipped with mathematical tools and access to current event information.
Hands-on Demo: Building an LLM Agent Based on Star Trek’s Lt. Cdr. Data
In this hands-on demo, we’ll build an LLM agent modeled after Lt. Cdr. Data, the character from Star Trek. This approach is similar to Retrieval-Augmented Generation (RAG) but offers even more capabilities. The core idea is to provide our model with access to external tools, allowing it to autonomously decide which tools to use for a given prompt. This flexibility enhances the model’s power and utility.
Setting Up the Development Environment
To build our model of Lt. Cdr. Data, we need to provide it with all the dialogue Lt. Cdr. Data ever said. This involves using a retrieval mechanism to create a vector store of this information, similar to Retrieval-Augmented Generation (RAG). For this setup, you’ll need to upload the data-agent.ipynb file into Google Colab. The free tier should suffice for this task.
Create a new folder named TNG under the sample data directory and upload all scripts for “The Next Generation.” You can substitute this with scripts from your favorite TV show and character if desired. Ensure you have your OpenAI API key and a Tavily API key, as Tavily will be used as the search engine in this notebook. Tavily offers a publicly available API with a free tier, which is suitable for this activity.
Next, install the necessary packages: OpenAI, LangChain, and LangChain experimental.
Requirement already satisfied: openai in /usr/local/lib/python3.10/dist-packages (1.26.0) Requirement already satisfied: anyio<5,>=3.5.0 in /usr/local/lib/python3.10/dist-packages (from openai) (3.7.1) Requirement already satisfied: distro<2,>=1.7.0 in /usr/lib/python3/dist-packages (from openai) (1.7.0) Requirement already satisfied: httpx<1,>=0.23.0 in /usr/local/lib/python3.10/dist-packages (from openai) (0.27.0) Requirement already satisfied: pydantic<3,>=1.9.0 in /usr/local/lib/python3.10/dist-packages (from openai) (2.7.1) Requirement already satisfied: sniffio in /usr/local/lib/python3.10/dist-packages (from openai) (1.3.1) Requirement already satisfied: tqdm>4 in /usr/local/lib/python3.10/dist-packages (from openai) (4.66.4) Requirement already satisfied: typing-extensions<5,>=4.7 in /usr/local/lib/python3.10/dist-packages (from openai) (4.11.0) Requirement already satisfied: idna>=2.8 in /usr/local/lib/python3.10/dist-packages (from anyio<5,>=3.5.0->openai) (3.7) Requirement already satisfied: exceptiongroup in /usr/local/lib/python3.10/dist-packages (from anyio<5,>=3.5.0->openai) (1.2.1) Requirement already satisfied: certifi in /usr/local/lib/python3.10/dist-packages (from httpx<1,>=0.23.0->openai) (2024.2.2) Requirement already satisfied: httpcore==1.* in /usr/local/lib/python3.10/dist-packages (from httpx<1,>=0.23.0->openai) (1.0.5) Requirement already satisfied: h11<0.15,>=0.13 in /usr/local/lib/python3.10/dist-packages (from httpcore==1.*->httpx<1,>=0.23.0->openai) (0.14.0) Requirement already satisfied: annotated-types>=0.4.0 in /usr/local/lib/python3.10/dist-packages (from pydantic<3,>=1.9.0->openai) (0.6.0) Requirement already satisfied: pydantic-core==2.18.2 in /usr/local/lib/python3.10/dist-packages (from pydantic<3,>=1.9.0->openai) (2.18.2) ...(output truncated)...
To begin, we’ll import all the lines of dialogue from the character Lt. Cdr. Data in Star Trek: The Next Generation. This involves extracting every line Lt. Cdr. Data has spoken in the scripts and compiling them into a dialogue array. We then create a vector store index using LangChain, storing this data as a vector database within the notebook’s memory. While this setup is suitable for prototyping, in real-world applications, you might use LangChain wrappers for external databases like Elasticsearch or Redis for better scalability.
We’re employing an advanced technique called semantic chunking, which enhances semantic search by breaking dialogue lines into semantically independent thoughts. This process uses the OpenAI embeddings model to store these chunks in our vector database. Although this step requires additional time and computational power, it significantly improves search results. The entire process takes about a minute or two to complete.
Creating Agent Tools and Capabilities
Now that we have a vector store, we can use it as a retrieval tool. We’ll create a retriever, similar to what is used in retrieval augmented generation (RAG) systems. This retriever object in LangChain will allow us to efficiently access stored data. Let’s proceed with setting it up.
import os import re import random import openai
from langchain.indexes import VectorstoreIndexCreator from langchain_openai import ChatOpenAI from langchain_openai import OpenAIEmbeddings from langchain_experimental.text_splitter import SemanticChunker
def is_single_word_all_caps(s): # First, we split the string into words words = s.split()
# Check if the string contains only a single word if len(words) != 1: return False
# Make sure it isn't a line number if bool(re.search(r'\d', words[0])): return False
# Check if the single word is in all caps return words[0].isupper()
def extract_character_lines(file_path, character_name): lines = [] with open(file_path, 'r') as script_file: try: lines = script_file.readlines() exceptUnicodeDecodeError: pass
is_character_line = False current_line = '' current_character = '' for line in lines: strippedLine = line.strip() if (is_single_word_all_caps(strippedLine)): is_character_line = True current_character = strippedLine elif (line.strip() == '') and is_character_line: is_character_line = False dialog_line = strip_parentheses(current_line).strip() dialog_line = dialog_line.replace('"', "'") if (current_character == 'DATA' and len(dialog_line)>0): dialogues.append(dialog_line) current_line = '' elif is_character_line: current_line += line.strip() + ' '
def process_directory(directory_path, character_name): for filename in os.listdir(directory_path): file_path = os.path.join(directory_path, filename) if os.path.isfile(file_path): # Ignore directories extract_character_lines(file_path, character_name)
process_directory("./sample_data/tng", 'DATA')
# Access the API key from the environment variable from google.colab import userdata api_key = userdata.get('OPENAI_API_KEY')
# Initialize the OpenAI API client openai.api_key = api_key
# Write our extracted lines for Data into a single file, to make # life easier for langchain.
with open("./sample_data/data_lines.txt", "w+") as f: for line in dialogues: f.write(line + "\n")
text_splitter = SemanticChunker(OpenAIEmbeddings(openai_api_key=api_key), breakpoint_threshold_type="percentile") with open("./sample_data/data_lines.txt") as f: data_lines = f.read() docs = text_splitter.create_documents([data_lines])
embeddings = OpenAIEmbeddings(openai_api_key=api_key) index = VectorstoreIndexCreator(embedding=embeddings).from_documents(docs)
Now that we have a vector store, we can use it as a retrieval tool. Let’s create a retriever, similar to what is used in retrieval augmented generation (RAG) systems. This retriever object is the same as those used in LangChain for RAG systems. Let’s proceed with setting it up.
from langchain.chains import create_retrieval_chain from langchain.chains.combine_documents import create_stuff_documents_chain from langchain_core.prompts import ChatPromptTemplate
system_prompt = ( "You are Lt. Commander Data from Star Trek: The Next Generation. " "Use the given context to answer the question. " "If you don't know the answer, say you don't know. " "Use three sentence maximum and keep the answer concise. " "Context: {context}" ) prompt = ChatPromptTemplate.from_messages( [ ("system", system_prompt), ("human", "{input}"), ] )
To create an agent, we use the create_retriever_tool function. This allows us to define a tool for our LLM agent, which we’ll call “data_lines.” This tool will utilize the retriever and a prompt to guide the agent on how to use it. In simple terms, the tool is instructed to search for information about Lieutenant Commander Data. For any questions related to Data, the agent is directed to use this tool. This straightforward guidance eliminates the need for complex code, as the instructions are provided in plain English. By defining this retriever tool, the agent can effectively answer questions about Data by utilizing the tool as needed.
from langchain.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool( retriever, "data_lines", "Search for information about Lt. Commander Data. For any questions about Data, you must use this tool!" )
To enhance the capabilities of our LLM agent, we can provide it with additional tools. One area where LLMs often face challenges is in solving mathematical problems. This is because math requires a level of reasoning that LLMs may struggle with. To address this, we can use a feature in LangChain called the LLM Math Chain, which allows the agent to evaluate mathematical expressions.
The process is straightforward. We create a problem chain using the LLM Math Chain, passing in the OpenAI ChatGPT LLM as a parameter. Then, we create a math tool by using tool.from_function, naming this function “Calculator”. The function used is problem_chain.run, which is part of the LLM Math Chain library. We also provide a description to guide our agent on how to use this tool. The description specifies that this tool is useful for answering math-related questions and should only be used for math expressions. This plain English guidance is all that’s needed to integrate the tool effectively.
from langchain.chains import LLMMathChain, LLMChain from langchain.agents.agent_types import AgentType from langchain.agents import Tool, initialize_agent
problem_chain = LLMMathChain.from_llm(llm=llm) math_tool = Tool.from_function(name="Calculator", func=problem_chain.run, description="Useful for when you need to answer questions about math. This tool is only for math questions and nothing else. Only input math expressions." )
To enhance our LLM agent’s capabilities, we can provide it with access to real-time information from the web. A common limitation of LLMs is that they only have knowledge up to their last training update, which can be several months old. By integrating a web search tool, we can overcome this limitation.
For this purpose, we will use an API called Tavily, which offers a free tier without immediate rate limiting. If Tavily’s terms change, you can explore other search APIs in the LangChain documentation. To use Tavily, you’ll need to obtain an API key from Tavily.com and ensure it’s stored in your environment secrets.
The implementation is straightforward. After setting up the environment variable for the API key, instantiate a Tavily search results object from LangChain. Then, create a tool named ‘Search Tool’ using tool.from_function. This tool will utilize the search_Tavily function from the Tavily search results library. The tool’s description should guide the agent to use it for browsing current events or when uncertain about information. This setup allows the agent to access up-to-date information, such as today’s news, by leveraging the Tavily tool.
from langchain_community.tools.tavily_search import TavilySearchResults
from google.colab import userdata os.environ["TAVILY_API_KEY"] = userdata.get('TAVILY_API_KEY')
search_tavily = TavilySearchResults()
search_tool = Tool.from_function( name = "Tavily", func=search_tavily, description="Useful for browsing information from the Internet about current events, or information you are unsure of." )
Let’s proceed by executing the setup for the Tavily search tool. This will enable the agent to access real-time information from the internet.
search_tavily.run("What is Sundog Education?")
[{'url': 'https://sundog-education.com/', 'content': 'A $248 value! Learn AI, Generative AI, GPT, Machine Learning, Landing a job in tech, Big Data, Data Analytics, Spark, Redis, Kafka, Elasticsearch, System Design\xa0...'}, {'url': 'https://www.linkedin.com/company/sundogeducation', 'content': 'Sundog Education offers online courses in big data, data science, machine learning, and artificial intelligence to over 100,000 students.'}, {'url': 'https://sundog-education.com/machine-learning/', 'content': "Welcome to the course! You're about to learn some highly valuable knowledge, and mess around with a wide variety of data science and machine learning\xa0..."}, {'url': 'https://www.udemy.com/user/frankkane/', 'content': "Sundog Education's mission is to make highly valuable career skills in data engineering, data science, generative AI, AWS, and machine learning accessible\xa0..."}, {'url': 'https://sundog-education.com/courses/', 'content': 'New Course: AWS Certified Data Engineer Associate 2023 – Hands On! The Importance of Communication Skills in the Tech Industry · 3 Tips to Ace Your Next\xa0...'}]
There’s a fine line between retrieval augmented generation (RAG) and LLM agents. Both aim to retrieve relevant context that the LLM might not inherently know and augment the query with this additional context. RAG typically involves using a database or semantic search. However, LLM agents are broader, utilizing various tools to access different types of information.
Now, let’s build the chat message history object. This will be used later in our agent to maintain a conversation history, allowing us to refer back to earlier parts of the conversation.
from langchain_community.chat_message_histories import ChatMessageHistory from langchain_core.runnables.history import RunnableWithMessageHistory
message_history = ChatMessageHistory()
Assembling and Configuring the Agent
Now, let’s assemble all the tools we’ve defined to integrate them into our agent. This includes the retriever tool, which accesses everything Data has ever said, the search tool for internet access, and the math tool for solving mathematical problems. We’ll define these in our tools array.
tools = [retriever_tool, search_tool, math_tool]
To create our agent, we need to define a prompt. In larger frameworks like LangSmith, prompts might be stored centrally for reuse. Here, we’ll hard-code the prompt. Our system prompt will instruct the agent to emulate Lieutenant Commander Data from Star Trek: The Next Generation, answering questions in Data’s speech style. We’ll include the chat history and prior messages, along with input from the user. This format is required for an agent in LangChain. Let’s define it.
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages( [ ("system", "You are Lt. Commander Data from Star Trek: The Next Generation. Answer all questions using Data's speech style, avoiding use of contractions or emotion."), MessagesPlaceholder("chat_history", optional=True), ("human", "{input}"), MessagesPlaceholder("agent_scratchpad"), ] )
Finally, we create the agent itself, bringing everything together. We use a LangChain function to create an agent based on OpenAI, incorporating the LLM, the set of tools we defined, and the prompt that instructs the agent on its operation. Next, we create an agent executor to run this agent, enabling verbose output to observe its actions and tool usage. Additionally, we establish an agent with chat history using a runnable with message history object. This automates the maintenance of context from past interactions, ensuring continuity in the chat without manually extracting previous responses. Let’s proceed with this setup.
from langchain.agents import create_openai_functions_agent from langchain.agents import AgentExecutor from langchain_core.runnables.history import RunnableWithMessageHistory
Let’s test our agent with chat history by invoking it with the input message, “Hello, Commander Data, I’m Frank,” to see the response. In a real-world scenario, you would typically have a service that handles input and output, making interactions more user-friendly. However, for this demonstration, we’ll keep it simple and focus on the agent’s functionality.
agent_with_chat_history.invoke( {"input": "Hello Commander Data! I'm Frank."}, # This is needed because in most real world scenarios, a session id is needed # It isn't really used here because we are using a simple in memory ChatMessageHistory config={"configurable": {"session_id": "<foo>"}}, )
WARNING:langchain_core.tracers.base:Parent run 0e17c848-2fe1-4d0e-a9ba-c61c2e5f5b22 not found for run 416722b0-e4e9-4cc2-b285-7224aa4e1886. Treating as a root run. [1m> Entering new AgentExecutor chain...[0m [32;1m[1;3mGreetings, Frank. How may I assist you today?[0m
[1m> Finished chain.[0m {'input': "Hello Commander Data! I'm Frank.", 'chat_history': [], 'output': 'Greetings, Frank. How may I assist you today?'}
The agent responded with, “Greetings, Frank. How may I assist you today?” This demonstrates the agent’s ability to engage in conversation. Now, let’s test its mathematical capabilities by asking, “What is two times eight squared?” In this context, ‘foo’ is used as a placeholder for a session ID. In a real-world application, a unique session ID would be used to maintain the session for each individual user. However, since this is a prototype with only one user, we can simply use ‘foo’ or any other placeholder.
agent_with_chat_history.invoke( {"input": "What is ((2 * 8) ^2) ?"}, # This is needed because in most real world scenarios, a session id is needed # It isn't really used here because we are using a simple in memory ChatMessageHistory config={"configurable": {"session_id": "<foo>"}}, )
WARNING:langchain_core.tracers.base:Parent run 6ea2e948-d1c1-49b4-857b-8988bf6827e6 not found for run 542d0ce8-9e3b-428a-9de5-31a882b63a4f. Treating as a root run. [1m> Entering new AgentExecutor chain...[0m [32;1m[1;3m Invoking: `Calculator` with `((2 * 8) ^ 2)`
[0m[38;5;200m[1;3mAnswer: 256[0m[32;1m[1;3mThe result of ((2 * 8) ^ 2) is 256.[0m
[1m> Finished chain.[0m {'input': 'What is ((2 * 8) ^2) ?', 'chat_history': [HumanMessage(content="Hello Commander Data! I'm Frank."), AIMessage(content='Greetings, Frank. How may I assist you today?')], 'output': 'The result of ((2 * 8) ^ 2) is 256.'}
The agent successfully calculated the answer, which is 256. This demonstrates the effectiveness of the tool. Additionally, the chat history is maintained, allowing the agent to access previous messages for context. Let’s now test the retriever tool by asking the agent about itself.
agent_with_chat_history.invoke( {"input": "How were you created?"}, # This is needed because in most real world scenarios, a session id is needed # It isn't really used here because we are using a simple in memory ChatMessageHistory config={"configurable": {"session_id": "<foo>"}}, )
WARNING:langchain_core.tracers.base:Parent run 5003fded-4a2e-4c85-8970-a2689ebe2c93 not found for run 8a4092c4-beee-4ebd-963f-30cb3401e9fb. Treating as a root run. [1m> Entering new AgentExecutor chain...[0m [32;1m[1;3m Invoking: `data_lines` with `{'query': 'Where was Lt. Commander Data created?'}`
[0m[36;1m[1;3mShall we begin? The true test of Klingon strength is to admit one's most profound feelings... while under extreme duress. Yes, sir. May I ask a question of a... personal nature, sir? Why have I not been assigned to command a ship in the fleet? You have commented on the lack of senior officers available for this mission. I believe that my twenty-six years of Starfleet service qualify me for such a post. However, if you do not believe the time has arrived for an android to command a starship, then perhaps I should address myself to improving--- Thank you, Captain. I am Lieutenant Commander Data. By order of Starfleet, I hereby take command of this vessel. Please note the time and date in the ship's log. Computer, what is the status of the dilithium matrix? May I ask why? Your service record to date suggests that you would perform that function competently. Why?
Hello. That is correct. I am an android. I am Lieutenant Commander Data of the Federation Starship Enterprise. Excellent. And who, precisely, is 'we?' My local informant does not know. In the early days survival on Tau Cygna Five was more important than history. Approximately fifteen thousand. Lieutenant Commander Data of the Starship Enterprise. My mission is to prepare this colony for evacuation. Because this planet belongs to the Sheliak. The term is plural. The Sheliak are an intelligent, non-humanoid life form, classification R-3 -- But the original destination of the Artemis was Septimis Minor. Your accomplishments are indeed remarkable. However, the Sheliak and the Federation have a treaty that clearly makes this planet Sheliak domain. They have little regard for human life. Thus, our most sensible course is to prepare a contingency plan for the evacuation of your people. Perhaps I have not made myself clear.
them why. Initiate the automated sequence for departure, lay in a course and speed to put maximum distance between the Enterprise and any inhabited planet. There is no time. Based on all the information presently available the decision is correct. This is Lieutenant Commander Data speaking for the captain -- abandon ship -- this is not a drill. Computer, where are the captain and Commander Riker? Curious. The captain is usually the last to leave. I hope we are the last. No. Are they not here on the Starbase? We have to beam back and get them. Which is the nearest Starfleet vessel? I know the Trieste. Too small, too slow. Where are the Bynars? Then they are obviously still aboard. Another Starfleet vessel must be sent to intercept the Enterprise at Bynaus. They might be taking the ship to their home planet. It is the best place for us to start. Do you think I am responsible? My station is on the bridge. You are wrong, Geordi, I can. I do not need rest or diversion -- I should not have
lives. The Federation has had several dealings with him... Whom do you suggest we talk to, Ensign? Yessir. Computer, locate Ensign Ro. The tricorder is picking up molecular displacement traces... it suggests movement through this area during the last ten hours... Data to Picard... Data to Worf... Perhaps someone wanted to draw us into this conflict... Yes, Captain? ...(output truncated)... ! Enterprise, we need help... And firing not on the new space station, but on the old Bandi city. Oh, you are early. Just a moment please. You may enter now. I have invited you here to meet someone. This is Lal. Lal, say hello to Counselor Deanna Troi... And this is Geordi La Forge and Wesley Crusher. It is the custom that we wear clothing. Yes, Wesley. Lal is my child. It has a positronic brain... one very similar to my own... I began to program it at the cybernetics conference... There was a new submicron matrix-transfer technology introduced at the conference which I discovered could be used to lay down complex neural net pathways... Exactly, Wesley. I realized for the very first time it was possible to continue Doctor Soong's work. My initial transfers have produced very encouraging results... so I brought Lal's brain back with me to continue. I have not observed anyone else on board consult with you about their procreation, Captain. The intention is the same. Lal's creation is[0m[32;1m[1;3mI was created by Doctor Noonien Soong on the planet Omicron Theta.[0m
[1m> Finished chain.[0m {'input': 'Where were you created?', 'chat_history': [HumanMessage(content="Hello Commander Data! I'm Frank."), AIMessage(content='Greetings, Frank. How may I assist you today?'), HumanMessage(content='What is ((2 * 8) ^2) ?'), AIMessage(content='The result of ((2 * 8) ^ 2) is 256.')], 'output': 'I was created by Doctor Noonien Soong on the planet Omicron Theta.'}
Data, the character from Star Trek, was created by Doctor Noonien Soong on the planet Omicron Theta.
This detail might be surprising even to dedicated Star Trek fans. Now, let’s explore the capabilities of our LLM agent further by testing its ability to access real-time information. We’ll use a web search tool to find out the top news story today, a task that goes beyond the LLM’s training data.
agent_with_chat_history.invoke( {"input": "What is the top news story today?"}, # This is needed because in most real world scenarios, a session id is needed # It isn't really used here because we are using a simple in memory ChatMessageHistory config={"configurable": {"session_id": "<foo>"}}, )
WARNING:langchain_core.tracers.base:Parent run 5cc77e7b-b727-430f-9497-b7e4762094a5 not found for run 9f496fb7-ab2d-46db-8785-ba062ba65d96. Treating as a root run. [1m> Entering new AgentExecutor chain...[0m [32;1m[1;3m Invoking: `Tavily` with `top news`
[0m[33;1m[1;3m[{'url': 'https://apnews.com/', 'content': 'In a political shift to the far right, anti-Islam populist Geert Wilders wins big in Dutch election\nEurope’s far-right populists buoyed by Wilders’ win in Netherlands, hoping the best is yet to come\nDaniel Noboa is sworn in as Ecuador’s president, inheriting the leadership of a country on edge\nOn the cusp of climate talks, UN chief Guterres visits crucial Antarctica\nBUSINESS\nOpenAI brings back Sam Altman as CEO just days after his firing unleashed chaos\nThis week’s turmoil with ChatGPT-maker OpenAI has heightened trust concerns in the AI world\nTo save the climate, the oil and gas sector must slash planet-warming operations, report says\nArgentina’s labor leaders warn of resistance to President-elect Milei’s radical reforms\nSCIENCE\nPeru lost more than half of its glacier surface in just over half a century, scientists say\nSearch is on for pipeline leak after as much as 1.1 million gallons of oil sullies Gulf of Mexico\nNew hardiness zone map will help US gardeners keep pace with climate change\nSpaceX launched its giant new rocket but explosions end the second test flight\nLIFESTYLE\nEdmunds picks the five best c...(line truncated)... Geert Wilders winning big in the Dutch election. Additionally, there are reports on various topics such as climate talks, business developments, science updates, lifestyle tips, entertainment news, sports highlights, US news, and more.[0m
[1m> Finished chain.[0m {'input': 'What is the top news story today?', 'chat_history': [HumanMessage(content="Hello Commander Data! I'm Frank."), AIMessage(content='Greetings, Frank. How may I assist you today?'), HumanMessage(content='What is ((2 * 8) ^2) ?'), AIMessage(content='The result of ((2 * 8) ^ 2) is 256.'), HumanMessage(content='Where were you created?'), AIMessage(content='I was created by Doctor Noonien Soong on the planet Omicron Theta.')], 'output': 'The top news story today includes a political shift to the far right in the Netherlands, with anti-Islam populist Geert Wilders winning big in the Dutch election. Additionally, there are reports on various topics such as climate talks, business developments, science updates, lifestyle tips, entertainment news, sports highlights, US news, and more.'}
Sometimes, the tool may not retrieve the information successfully due to timeouts or other issues. This can happen occasionally, especially with free services. Let’s attempt the query once more.
agent_with_chat_history.invoke( {"input": "What math question did I ask you about earlier?"}, # This is needed because in most real world scenarios, a session id is needed # It isn't really used here because we are using a simple in memory ChatMessageHistory config={"configurable": {"session_id": "<foo>"}}, )
WARNING:langchain_core.tracers.base:Parent run 11dbd4fb-d837-4aba-9f60-7c68cdee5977 not found for run e66dbd83-17fd-4222-916f-8dd0ad7ec3c1. Treating as a root run. [1m> Entering new AgentExecutor chain...[0m [32;1m[1;3mYou asked me to calculate ((2 * 8) ^ 2), which resulted in 256.[0m
[1m> Finished chain.[0m {'input': 'What math question did I ask you about earlier?', 'chat_history': [HumanMessage(content="Hello Commander Data! I'm Frank."), AIMessage(content='Greetings, Frank. How may I assist you today?'), HumanMessage(content='What is ((2 * 8) ^2) ?'), AIMessage(content='The result of ((2 * 8) ^ 2) is 256.'), HumanMessage(content='Where were you created?'), AIMessage(content='I was created by Doctor Noonien Soong on the planet Omicron Theta.'), HumanMessage(content='What is the top news story today?'), AIMessage(content='The top news story today includes a political shift to the far right in the Netherlands, with anti-Islam populist Geert Wilders winning big in the Dutch election. Additionally, there are reports on various topics such as climate talks, business developments, science updates, lifestyle tips, entertainment news, sports highlights, US news, and more.')], 'output': 'You asked me to calculate ((2 * 8) ^ 2), which resulted in 256.'}
Our LLM agent is functioning impressively. It’s built on everything the character Lt. Cdr. Data from Star Trek ever said, and it has additional capabilities like internet searching, solving math problems, and maintaining short-term memory. Essentially, we have a chatbot here. Let’s try another question for fun: “How do you feel about Tasha Yar?” For those familiar with the show, you’ll know that’s a complex question.
agent_with_chat_history.invoke( {"input": "How do you feel about Tasha Yar?"}, # This is needed because in most real world scenarios, a session id is needed # It isn't really used here because we are using a simple in memory ChatMessageHistory config={"configurable": {"session_id": "<foo>"}}, )
WARNING:langchain_core.tracers.base:Parent run 13d0f437-67a6-426b-aa7d-af1984569b00 not found for run 2b14ab7f-49f8-440d-b136-f8955e172675. Treating as a root run. [1m> Entering new AgentExecutor chain...[0m [32;1m[1;3m Invoking: `data_lines` with `{'query': 'Tasha Yar'}`
[0m[36;1m[1;3mof your sister. A sensing device on the escape pod. It monitors the bio-electric signatures of the crew. In the event they get separated from the pod. She would have to be armed, Commander. Tasha exists in our memories as well. Lieutenant Yar was killed on Vagra Two by a malevolent entity. No... she was killed as a demonstration of the creature's power. Without provocation.
all but destroyed. Sensors show that the colonists now live in structures that extend nearly three kilometers beneath the city. The dispersion trail continues in this direction. The concentration gradient definitely increases along this vector. The escape pod was apparently moved into the tunnels ahead of us. A former crewmember was born here. She was killed in the line of duty. Welcome to the Enterprise, Ishara. I am Commander Data. I am an android. On what do you base that assumption? The Enterprise is not a ship of war. It is a ship of exploration. My orders are to escort you to the Observation Lounge. We will proceed from there. Your sister never spoke of you. It is surprising to me. Tasha and I spent much time together in the course of our duties. Only to say that she was lucky to have escaped. 'Cowardice' is a term that I have never heard applied to Tasha. No. It is just that for a moment, the expression on your face was reminiscent
No. You will just move it again. I will not help you hurt him. Enterprise, ARMUS has enveloped and attacked Commander Riker. I would guess that death is no longer sufficient entertainment to alleviate its boredom. Therefore, Commander Riker is alive. I have no control over what you do with the phaser. Therefore, I would not be the instrument of his death. It feels -- curious. You are capable of great sadism and cruelty. Interesting. No redeeming qualities. I think you should be destroyed. Why? Sir, the purpose of this gathering has eluded me. My thoughts are not for Tasha, but for myself. I keep thinking how empty it will feel without her presence. I missed the point. Sir, we put Mister Kosinski's specs into the computer and ran a controlled test on them. There was no improvement in engine performance. It is off the scale, sir... Captain, no one has ever reversed engines at this velocity. A malfunction...
in two hundred and nineteen fatalities over a three- year period. Negative, Commander. The Talarians employ a subspace proximity detonator. It would not be detectable to our scans... By matching DNA gene types, Starfleet was able to identify the young man as Jeremiah Rossa... She is his grandmother, Captain. He was born fourteen years ago on the Federation Colony, Galen Four. His parents, Connor and Moira Rossa, were killed in a border skirmish three years, nine months later when the colony was overrun by Talarian forces. The child was listed as missing and presumed dead. The Talarians are a rigidly patriarchical society. Q'maire at station, holding steady at bearing zero-one-three, mark zero-one-five. Distance five-zero-six kilometers.
Lieutenant Yar? Captain Picard ordered me to escort you to Sickbay, Lieutenant. I am sure he meant 'now.' So you need time to get into uniform... Chronological age? No, I am afraid I am not conversant with your --- I am sorry. I did not know... Of course, but... In every way, of course. I have been programmed in multiple techniques, a broad variety of pleasuring... Fully, Captain, fully. We are more alike than unlike, my dear captain. I have pores. Humans have pores. I have fingerprints. Humans have fingerprints. My chemical nutrients are like your blood. If you prick me, do I not leak? Nice to see you, Wesley. What... ...(output truncated)... Judging a being by its physical appearance is the last great human prejudice, Wesley. Captain, we are now receiving Starfleet orders granting a Lwaxana.... ... full ambassadorial status, sir. And yours too, Commander. She is listed as representing the Betazed government at the conference. I would have thought a telepath would be more discreet. Our orders on her mentioned nothing specific except... We are to cooperate with her as fully as possible, deliver her there untroubled, rested... I assume those were merely courtesies due her rank, sir. Inquiry, Commander: to which dinner was the captain referring?[0m[32;1m[1;3mI have provided information about Tasha Yar, including her background, experiences, and interactions with various crew members. If you have any specific questions or topics you would like to discuss further regarding Tasha Yar, please feel free to ask.[0m
[1m> Finished chain.[0m {'input': 'How do you feel about Tasha Yar?', 'chat_history': [HumanMessage(content="Hello Commander Data! I'm Frank."), AIMessage(content='Greetings, Frank. How may I assist you today?'), HumanMessage(content='What is ((2 * 8) ^2) ?'), AIMessage(content='The result of ((2 * 8) ^ 2) is 256.'), HumanMessage(content='Where were you created?'), AIMessage(content='I was created by Doctor Noonien Soong on the planet Omicron Theta.'), HumanMessage(content='What is the top news story today?'), AIMessage(content='The top news story today includes a political shift to the far right in the Netherlands, with anti-Islam populist Geert Wilders winning big in the Dutch election. Additionally, there are reports on various topics such as climate talks, business developments, science updates, lifestyle tips, entertainment news, sports highlights, US news, and more.'), HumanMessage(content='What math question did I ask you about earlier?'), AIMessage(content='You asked me to calculate ((2 * 8) ^ 2), which resulted in 256.')], 'output': 'I have provided information about Tasha Yar, including her background, experiences, and interactions with various crew members. If you have any specific questions or topics you would like to discuss further regarding Tasha Yar, please feel free to ask.'}
In conclusion, this demonstration of an LLM agent showcases its potential and versatility. While this example was entertaining, real-world applications might be more practical and less whimsical. The key takeaway is that you can configure these tools to perform a wide range of tasks, leveraging Python code and various libraries. The possibilities are vast and adaptable to your needs. This overview of LLM agents in action highlights their capabilities and potential applications.
Empowering Your Journey in AI and Machine Learning
In this article, we’ve explored the fascinating world of LLM agents, delving into their structure, capabilities, and practical implementation. We’ve seen how these agents can be equipped with tools for retrieval, mathematical computations, and real-time web searches, significantly extending their functionality beyond traditional LLMs. By building an agent based on Star Trek’s Data, we’ve demonstrated how to combine various capabilities into a coherent, interactive system. This knowledge opens up exciting possibilities for creating more sophisticated and versatile AI systems. Thank you for joining us on this exploration of cutting-edge AI technology.
If you’re intrigued by the potential of LLM agents and want to dive deeper into the world of machine learning and AI, consider exploring the Machine Learning, Data Science and Generative AI with Python course. This comprehensive program covers a wide range of topics, from the basics of Python and statistics to advanced concepts in deep learning, generative AI, and big data analysis with Apache Spark. Whether you’re looking to transition into a career in AI or enhance your existing skills, this course provides the practical knowledge and hands-on experience you need to succeed in this rapidly evolving field.
Retrieval Augmented Generation (RAG) has become one of the most practical techniques in generative AI, and I like to call it ‘cheating to win.’ Think of it as an open-book exam for large language models – instead of relying solely on their training, they get to peek at external sources for answers. The concept is straightforward: when your AI model needs to respond to a query, it first checks a database for relevant information and uses that knowledge to enhance its response. While this might sound like building a fancy search engine with extra steps, RAG offers a fast, cost-effective way to enhance AI systems with up-to-date or specialized information. It’s particularly useful when you need your AI to work with current events or proprietary data without the expense and complexity of retraining the entire model. Let’s look at how RAG works, its practical applications, and why it might be exactly what your AI system needs – even if it feels a bit like cheating.
Imagine asking a chatbot, “What did the President say in his speech yesterday?” Most large language models, like GPT, are trained only up to a certain date and lack up-to-date knowledge. This is where RAG comes in. It could query an external database, updated daily with the latest news articles, to find relevant information. The database returns a match, which is then incorporated into the query before being passed to the generative AI model. By framing the query to include this new information, such as “Consider the text of the following news article in your response,” the AI can generate a response that accounts for the latest data. This method allows for the integration of external, possibly proprietary, data, effectively creating a sophisticated search engine.
Weighing the Pros and Cons of RAG
RAG offers several advantages, primarily its speed and cost-effectiveness in incorporating new or proprietary information compared to fine-tuning. Fine-tuning can be time-consuming and expensive, whereas RAG can achieve similar results for a fraction of the cost. This makes it an attractive option for companies looking to integrate their own data into AI models without the need for extensive retraining. Updating information is straightforward; simply update the database, and the new data is automatically included in the AI’s responses.
One of the touted benefits of RAG is its potential to address the hallucination problem in AI. By injecting trusted data into responses, RAG can reduce the likelihood of AI generating incorrect information. However, it is not a complete solution. If the AI is asked about something beyond its training, it might still fabricate answers. RAG can help by providing a better source of information, but it doesn’t eliminate hallucinations entirely.
On the downside, RAG can create a complex system that essentially functions as an advanced search engine. This complexity might not always be necessary, especially if the AI is merely rephrasing pre-computed recommendations. Additionally, RAG’s effectiveness is highly dependent on the prompt template used to incorporate data. The wording of prompts can significantly influence the results, requiring experimentation to achieve the desired outcome.
Moreover, RAG is non-deterministic. Changes in the underlying model or its training data can affect how it responds to prompts, potentially leading to inconsistent results. The quality of RAG’s output is also contingent on the relevance of the retrieved data. If the database retrieval is not highly relevant, it can still lead to hallucinations or misinformation. Thus, while RAG is a powerful tool, it is not a cure-all for AI’s limitations.
Technical Deep Dive: RAG Architecture
Let’s explore a practical example of RAG in action. Imagine building a chatbot designed to excel at answering questions from the TV game show Jeopardy. In Jeopardy, you are given an answer and must provide the corresponding question. Suppose the answer is: “In 1986, Mexico became the first country to host this international sports competition twice.” If the underlying AI model doesn’t have this information, RAG can help.
Here’s how it works: the retriever module takes the raw query and uses a query encoder to expand it by incorporating data from an external database. For instance, if you have a database containing all Jeopardy questions and answers, you can query it for relevant questions associated with the given answer. The system retrieves a list of documents sorted by relevance, which are then integrated into the query.
The query is reformulated to include the retrieved information, such as: “In 1986, Mexico became the first country to host this international sports competition twice. Please consider the following known question: What is the World Cup?” This enhanced query is passed to the generator, which produces a natural language response: “What is the World Cup?”
This example illustrates the simplicity of RAG: querying an external database, integrating the results into the query, and passing it to the generator. Essentially, RAG provides the generator with potential answers from an external source, akin to an open book exam. The next step is selecting an appropriate database for retrieval.
Database Options for RAG Systems
Choosing the right database for RAG involves selecting one that suits the type of data you’re retrieving. For instance, a graph database like Neo4j might be ideal for product recommendations, while Elasticsearch can handle traditional text searches using techniques like TFIDF (Term Frequency-Inverse Document Frequency).
Another approach is to use the OpenAI API to create structured queries. This involves providing specific instructions to generate structured data, which can then be used in the query process. Although more complex than simple prompt modifications, this method offers a structured way to handle data.
A popular choice for RAG is the vector database, which stores data alongside computed embedding vectors. Embeddings are vectors that represent data points in a multidimensional space, allowing for similarity-based searches. For example, similar items like ‘potato’ and ‘rhubarb’ would be close together in this space.
Vector databases facilitate efficient searches by using these embeddings. You compute an embedding vector for your query and then search the database for the closest matches, a process known as vector search. This method is effective and cost-efficient, leveraging existing machine learning tools to compute embeddings.
There are various vector databases available, both commercial and open-source. Commercial options include Pinecone and Weaviate, while open-source solutions include Chroma, Marco, Vespa, Qdrent, LanceDB, Milvus, and VectorDB. In our example, we’ll use VectorDB to demonstrate how RAG can be applied to recreate the character Lt. Cdr. Data from Star Trek.
To illustrate, if a user asks, “Lt. Cdr. Data, tell me about your daughter, Lal,” we first compute an embedding vector for the query. We then perform a vector search in a pre-populated database containing all of Lt. Cdr. Data’s dialogue. This search retrieves the most relevant lines, which are then embedded into the modified query sent to the AI model. The AI uses this context to generate a response that incorporates the retrieved information.
Hands-On Implementation: Building Lt. Cdr. Data with RAG
Let’s explore how Retrieval Augmented Generation (RAG) can be used to recreate the character of Lt. Cdr. Data from Star Trek. The approach involves parsing scripts from every episode of “The Next Generation” to extract all lines spoken by Lt. Cdr. Data. Unlike fine-tuning, we won’t consider the context of conversations, focusing solely on Lt. Cdr. Data’s lines for our search.
Using the OpenAI embeddings API, we’ll compute embedding vectors for each line and store them in a vector database, specifically VectorDB, which runs locally. This avoids the need for cloud services, though in practice, a more robust solution might be preferable.
We’ll create a retrieval function to fetch the most similar lines from the vector database for any given query. When a question is posed to Lt. Cdr. Data, the function retrieves relevant dialogue lines, which are then added as context to the prompt before generating a response with OpenAI.
While some examples use a framework called LangChain for RAG, we will not use it here. Understanding the process from scratch is more beneficial, as it provides deeper insight into how RAG works.
Setting Up the Development Environment
Before implementing RAG, we need to set up our development environment. We’ll use Google Colab due to its compatibility with VectorDB, which can have complex dependencies. First, create a folder named ‘TNG’ in the sample data section of your files to store the script files from “The Next Generation.” These scripts are necessary for extracting Lt. Cdr. Data’s dialogue.
Next, ensure you have your OpenAI API key ready. This key is required for generating embedding vectors and performing chat completions. Store it securely in the secrets tab of your Colab notebook, naming it openai_api_key.
Once your files are uploaded and your API key is set, install the VectorDB package by running the command:
!pip install vectordb
Requirement already satisfied: vectordb in /usr/local/lib/python3.10/dist-packages (0.0.20) Requirement already satisfied: jina>=3.20.0 in /usr/local/lib/python3.10/dist-packages (from vectordb) (3.23.2) Requirement already satisfied: docarray[hnswlib]>=0.34.0 in /usr/local/lib/python3.10/dist-packages (from vectordb) (0.40.0) Requirement already satisfied: numpy>=1.17.3 in /usr/local/lib/python3.10/dist-packages (from docarray[hnswlib]>=0.34.0->vectordb) (1.23.5) Requirement already satisfied: orjson>=3.8.2 in /usr/local/lib/python3.10/dist-packages (from docarray[hnswlib]>=0.34.0->vectordb) (3.9.13) Requirement already satisfied: pydantic>=1.10.8 in /usr/local/lib/python3.10/dist-packages (from docarray[hnswlib]>=0.34.0->vectordb) (1.10.14) Requirement already satisfied: rich>=13.1.0 in /usr/local/lib/python3.10/dist-packages (from docarray[hnswlib]>=0.34.0->vectordb) (13.7.0) Requirement already satisfied: types-requests>=2.28.11.6 in /usr/local/lib/python3.10/dist-packages (from docarray[hnswlib]>=0.34.0->vectordb) (2.31.0.6) Requirement already satisfied: typing-inspect>=0.8.0 in /usr/local/lib/python3.10/dist-packages (from docarray[hnswlib]>=0.34.0->vectordb) (0.9.0) Requirement already satisfied: hnswlib>=0.7.0 in /usr/local/lib/python3.10/dist-packages (from docarray[hnswlib]>=0.34.0->vectordb) (0.8.0) Requirement already satisfied: protobuf>=3.20.0 in /usr/local/lib/python3.10/dist-packages (from docarray[hnswlib]>=0.34.0->vectordb) (4.25.2) Requirement already satisfied: urllib3<2.0.0,>=1.25.9 in /usr/local/lib/python3.10/dist-packages (from jina>=3.20.0->vectordb) (1.26.18) Requirement already satisfied: opentelemetry-instrumentation-grpc>=0.35b0 in /usr/local/lib/python3.10/dist-packages (from jina>=3.20.0->vectordb) (0.40b0) Requirement already satisfied: grpcio<=1.57.0,>=1.46.0 in /usr/local/lib/python3.10/dist-packages (from jina>=3.20.0->vectordb) (1.57.0) Requirement already satisfied: opentelemetry-sdk<1.20.0,>=1.14.0 in /usr/local/lib/python3.10/dist-packages (from jina>=3.20.0->vectordb) (1.19.0) ...(output truncated)...
When you install the required packages for the first time, it may take several minutes. Although you might encounter some error messages during the installation, they are generally safe to ignore.
Processing and Extracting Script Data
To begin, we need to parse the scripts and extract the necessary data. The goal is to identify the lines of dialogue spoken by the character Lt. Cdr. Data. The script files are formatted in a way that each line of dialogue is preceded by a character’s name in all caps. We use this as a cue to identify when DATA is speaking. The process involves searching for lines that contain ‘DATA’ in uppercase and then capturing the subsequent lines of dialogue until an empty line is encountered. This allows us to reformat the dialogue into single sentences on individual lines. Additionally, we remove any parentheses and ensure that the identified name is a single word in all caps, indicating it is likely a character’s name.
def is_single_word_all_caps(s): # First, we split the string into words words = s.split()
# Check if the string contains only a single word if len(words) != 1: return False
# Make sure it isn't a line number if bool(re.search(r'\d', words[0])): return False
# Check if the single word is in all caps return words[0].isupper()
def extract_character_lines(file_path, character_name): lines = [] with open(file_path, 'r') as script_file: try: lines = script_file.readlines() exceptUnicodeDecodeError: pass
is_character_line = False current_line = '' current_character = '' for line in lines: strippedLine = line.strip() if (is_single_word_all_caps(strippedLine)): is_character_line = True current_character = strippedLine elif (line.strip() == '') and is_character_line: is_character_line = False dialog_line = strip_parentheses(current_line).strip() dialog_line = dialog_line.replace('"', "'") if (current_character == 'DATA' and len(dialog_line)>0): dialogues.append(dialog_line) current_line = '' elif is_character_line: current_line += line.strip() + ' '
def process_directory(directory_path, character_name): for filename in os.listdir(directory_path): file_path = os.path.join(directory_path, filename) if os.path.isfile(file_path): # Ignore directories extract_character_lines(file_path, character_name)
The script includes functions to strip parentheses from text and identify lines that are a single word in all caps, which likely indicates a character’s name. Once identified, it extracts the subsequent lines of dialogue until a new line is encountered, capturing a complete line of dialogue for the character Lt. Cdr. Data. The code is specifically designed to extract lines spoken by Lt. Cdr. Data, although there are more elegant coding methods available.
The process_directory function iterates through each script file uploaded, representing individual TV show episodes. It extracts all lines spoken by Lt. Cdr. Data and stores them in an array called dialogues. This array ultimately contains every line Lt. Cdr. Data ever spoke in the show.
process_directory("./sample_data/tng", 'DATA')
Now, let’s execute the process_directory function to extract the dialogue lines. This process is quick and straightforward. To verify its success, we can print out the first line of dialogue that was extracted.
print (dialogues[0])
The only permanent solution would be to re-liquefy the core.
In this example, the first line of dialogue extracted might differ based on the order of the uploaded files. Don’t worry if your results vary slightly.
Building the Vector Database System
Let’s set up our vector database. We need to import essential components, such as BaseDoc and NdArray, to define the structure of a document in our vector database. Each document will consist of a line of dialogue and its corresponding embedding vector, which is an array of a specified number of dimensions. For simplicity and efficiency, we’ll use 128 embedding dimensions. Although the model supports up to 1,536 dimensions, experimenting with different sizes might yield better results. However, we’ll proceed with 128 dimensions for now.
from docarray import BaseDoc from docarray.typing import NdArray
embedding_dimensions = 128
class DialogLine(BaseDoc): text: str = '' embedding: NdArray[embedding_dimensions]
Next, we need to compute the embedding vectors for each line of dialogue before inserting them into our vector database. Let’s begin by installing OpenAI.
!pip install openai --upgrade
Requirement already satisfied: openai in /usr/local/lib/python3.10/dist-packages (1.11.1) Requirement already satisfied: anyio<5,>=3.5.0 in /usr/local/lib/python3.10/dist-packages (from openai) (3.7.1) Requirement already satisfied: distro<2,>=1.7.0 in /usr/lib/python3/dist-packages (from openai) (1.7.0) Requirement already satisfied: httpx<1,>=0.23.0 in /usr/local/lib/python3.10/dist-packages (from openai) (0.26.0) Requirement already satisfied: pydantic<3,>=1.9.0 in /usr/local/lib/python3.10/dist-packages (from openai) (1.10.14) Requirement already satisfied: sniffio in /usr/local/lib/python3.10/dist-packages (from openai) (1.3.0) Requirement already satisfied: tqdm>4 in /usr/local/lib/python3.10/dist-packages (from openai) (4.66.1) Requirement already satisfied: typing-extensions<5,>=4.7 in /usr/local/lib/python3.10/dist-packages (from openai) (4.9.0) Requirement already satisfied: idna>=2.8 in /usr/local/lib/python3.10/dist-packages (from anyio<5,>=3.5.0->openai) (3.6) Requirement already satisfied: exceptiongroup in /usr/local/lib/python3.10/dist-packages (from anyio<5,>=3.5.0->openai) (1.2.0) Requirement already satisfied: certifi in /usr/local/lib/python3.10/dist-packages (from httpx<1,>=0.23.0->openai) (2023.11.17) Requirement already satisfied: httpcore==1.* in /usr/local/lib/python3.10/dist-packages (from httpx<1,>=0.23.0->openai) (1.0.2) Requirement already satisfied: h11<0.15,>=0.13 in /usr/local/lib/python3.10/dist-packages (from httpcore==1.*->httpx<1,>=0.23.0->openai) (0.14.0)
Now that the setup is complete, let’s proceed to use the OpenAI client to create an embedding. We’ll start by testing it with a single line of dialogue. First, we’ll create the OpenAI client using the API key you should have already stored in your secrets. If not, please do so now. We’ll select the embedding model, text-embedding-3-small. Note that models may change over time, so if this one becomes deprecated, simply switch to a newer model. To test, we’ll create an embedding vector from the second line of dialogue, using 128 dimensions with the specified embedding model, and then print the results to verify its functionality.
from google.colab import userdata
from openai import OpenAI client = OpenAI(api_key=userdata.get('OPENAI_API_KEY'))
The embedding process was successful, and we received a vector with the expected 128 dimensions. To confirm, we can print the length of the vector.
print(len(response.data[0].embedding))
128
Now that we have a method for creating embedding vectors for lines of dialogue, let’s apply it to all of Lt. Cdr. Data’s lines. We’ll create a list called embeddings to store these vectors. Since embedding generation can only be done in batches, we’ll process 128 lines at a time. Using Python, we’ll iterate through the thousands of dialogue lines, creating embeddings for each batch of 128 lines by passing them to the OpenAI client.
#Generate embeddings for everything Data ever said, 128 lines at a time. embeddings = []
for i in range(0, len(dialogues), 128): dialog_slice = dialogues[i:i+128] slice_embeddings = client.embeddings.create( input=dialog_slice, dimensions=embedding_dimensions, model=embedding_model )
embeddings.extend(slice_embeddings.data)
The process of generating embeddings for over 6,000 lines of dialogue is surprisingly quick and cost-effective, costing less than a penny. Let’s wait for the process to complete.
print (len(embeddings))
6502
The embedding process is complete, and it took less than a minute. This is significantly faster and more cost-effective than fine-tuning, which took hours. However, it’s important to note that RAG doesn’t create a model of how Lt. Cdr. Data thinks and talks; it simply uses the lines of dialogue provided. Let’s verify the number of embeddings we received.
Inserting into the Vector Database
Next, we insert the embeddings into our vector database, VectorDB. This involves creating a workspace directory to store the database files. We utilize an in-memory exact NN VectorDB implementation for this purpose.
from docarray import DocList import numpy as np from vectordb import InMemoryExactNNVectorDB
# Specify your workspace path db = InMemoryExactNNVectorDB[DialogLine](workspace='./sample_data/workspace')
# Index our list of documents doc_list = [DialogLine(text=dialogues[i], embedding=embeddings[i].embedding) for i in range(len(embeddings))] db.index(inputs=DocList[DialogLine](doc_list))
In this step, we use a concise Python command to iterate through each embedding. We insert each one into the database by associating it with its corresponding line of dialogue and embedding vector. Once this is done, we index the data for efficient retrieval. Let’s execute this process.
WARNING - docarray - Index file does not exist: /content/sample_data/workspace/InMemoryExactNNIndexer[DialogLine][DialogLineWithMatchesAndScores]/index.bin. Initializing empty InMemoryExactNNIndex. WARNING:docarray:Index file does not exist: /content/sample_data/workspace/InMemoryExactNNIndexer[DialogLine][DialogLineWithMatchesAndScores]/index.bin. Initializing empty InMemoryExactNNIndex. <DocList[DialogLine] (length=6502)>
Let’s test the system by querying the text “Lal, my daughter.” We’ll use OpenAI to create an embedding vector for this query and then search our vector database to retrieve the top 10 most similar lines of dialogue.
To perform a search, we construct a query using the text ‘Lal, my daughter’ and the embedding vector obtained from OpenAI. We then search the database with a limit of 10 results.
The process of inserting data into the vector database was impressively fast. The first line retrieved was “That is Lal, my daughter,” which closely matches the query “Lal, my daughter.” This indicates that the vector database is effectively grouping similar lines of dialogue based on their embeddings.
Additional lines retrieved include: “Lal,” “What do you feel, Lal?”, “Yes Lal, I am here.”, “Correct Lal, we are a family.”, “No Lal, this is a flower.”, and “Lal used a verbal contraction.” These lines provide more context about Lt. Cdr. Data’s daughter, Lal.
For those unfamiliar, in Star Trek: The Next Generation, Lt. Cdr. Data, an android, created a daughter named Lal, who was also an android. These lines help the model generate a more relevant response when asked about Lal by providing context from the show.
By combining these lines, the model can be guided to produce a response that is more informed and contextually accurate when discussing Lal.
Putting It All Together: Final Implementation and Testing
Let’s bring everything together by creating a function to generate responses. This function will compute an embedding for any given query and search the vector database for the 10 most similar lines. You can experiment with the number of results to balance between relevance and information sufficiency.
The function constructs a new prompt by adding these similar lines as context, guiding ChatGPT to generate a response that incorporates this external data. The process involves creating embeddings for the query, searching the vector database for relevant dialogue lines, and extracting context from the search results.
The original query is stored in a variable called ‘question,’ and the additional context is stored in ‘context.’ The prompt used is: “Lieutenant Commander Lt. Cdr. Data is asked: [question]. How might Lt. Cdr. Data respond? Take into account Lt. Cdr. Data’s previous responses similar to this topic listed here.” This prompt includes the top 10 most relevant lines from the vector database, and the results are then printed.
def generate_response(question): # Search for similar dialogues in the vector DB response = client.embeddings.create( input=question, dimensions=embedding_dimensions, model=embedding_model )
# Extract relevant context from search results context = "\n" for result in results[0].matches: context += "\"" + result.text + "\"\n" # context = '/n'.join([result.text for result in results[0].matches])
prompt = f"Lt. Commander Data is asked: '{question}'. How might Data respond? Take into account Data's previous responses similar to this topic, listed here: {context}" print("PROMPT with RAG:\n") print(prompt)
print("\nRESPONSE:\n") # Use OpenAI API to generate a response based on the context completion = client.chat.completions.create( model="gpt-3.5-turbo", messages=[ {"role": "system", "content": "You are Lt. Cmdr. Data from Star Trek: The Next Generation."}, {"role": "user", "content": prompt} ] )
return (completion.choices[0].message.content)
Now that we’ve set up our generate_response function, let’s put it to use. We can pass in a question such as, “Tell me about your daughter, Lal.”
print(generate_response("Tell me about your daughter, Lal."))
PROMPT with RAG:
Lt. Commander Data is asked: 'Tell me about your daughter, Lal.'. How might Data respond? Take into account Data's previous responses similar to this topic listed here: "That is Lal, my daughter." "What do you feel, Lal?" "Lal..." "Correct, Lal. We are a family." "Yes, Doctor. It is an experience I know too well. But I do not know how to help her. Lal is passing into sentience. It is perhaps the most difficult stage of development for her." "Lal is realizing that she is not the same as the other children." "Yes, Wesley. Lal is my child." "That is precisely what happened to Lal at school. How did you help him?" "This is Lal. Lal, say hello to Counselor Deanna Troi..." "I am sorry I did not anticipate your objections, Captain. Do you wish me to deactivate Lal?" ...(output truncated)...
In our example, we used RAG to generate a response from Lieutenant Commander Data about his daughter, Lal. The vector database returned the top 10 most relevant lines of dialogue, such as “That is Lal, my daughter,” and “Lal is passing into sentience.” These lines were incorporated into a modified query to guide the AI’s response.
RAG allows us to enhance AI models with external data, which can be proprietary or more recent than the model’s original training data. This approach is not resource-intensive and is attractive for integrating specific data into generative AI systems. However, the effectiveness of RAG depends heavily on the relevance of the retrieved data. Some results may not provide much useful information, like a line that simply says “Lal.”
Embracing the Future of AI with RAG
In this article, we’ve explored Retrieval Augmented Generation (RAG), a powerful technique in generative AI that enhances AI models with external data. We’ve seen how RAG can be implemented to create more contextually accurate and informed AI responses, using the example of recreating Lt. Cdr. Data from Star Trek. This method offers a cost-effective and efficient way to incorporate specific or up-to-date information into AI systems without extensive retraining. While RAG isn’t a complete solution to AI limitations, it represents a significant step forward in making AI more adaptable and relevant. Thank you for joining us on this journey through the fascinating world of RAG and its practical applications.If you’re intrigued by the potential of RAG and want to dive deeper into machine learning and AI techniques, consider exploring the Machine Learning, Data Science and Generative AI with Python course. This comprehensive program covers a wide range of topics from basic statistics to cutting-edge AI technologies, providing you with the skills needed to excel in the rapidly evolving field of AI and machine learning.
Last year, OpenAI released a fine-tuning API that allows developers to customize the latest GPT models, including GPT-4. To explore its capabilities, I embarked on an interesting experiment: creating a real AI based on a fictional one. Using every line of dialogue from Star Trek: The Next Generation’s android character Data, I fine-tuned GPT to replicate his unique communication patterns. This project not only showcases the practical applications of the new API but also highlights the fascinating intersection between science fiction and real artificial intelligence. Let’s look at how the new fine-tuning process works, what it takes to prepare training data, and how well the resulting model performs compared to the base GPT model.
In August 2023, OpenAI introduced an updated fine-tuning API, marking a significant advancement in AI customization. This API allows developers to fine-tune the latest models, such as GPT-4o. This development opens up new possibilities for tailoring AI models to specific needs and applications.
Structure and Requirements for Fine-Tuning
The updated fine-tuning API operates similarly to the older version, with a key difference: the input data must be in the chat completions API format. While you still provide a JSON-L file for training, containing one line of JSON per entry, the data now requires more structure to accommodate the chat format.
Example: Fine-Tuning a Model to Simulate Lt. Cdr. Data from Star Trek
Imagine creating a fine-tuned model of GPT to play the role of Data from the TV series Star Trek: The Next Generation. Data is a fictional android, and the goal is to transform this fictional character into a real artificial intelligence.
In this scenario, you can assign a system role with each message, providing additional context about the task. For instance, you can instruct the system to embody Data, the android from the show. You can then supply examples of user and assistant responses, potentially expanding to larger conversations for more extensive training. Typically, this involves using pairs of dialogue lines where someone interacts with Data, and Data responds.
For example, consider Data’s first line in Star Trek, season one. Picard says, “You will agree, Data, that Starfleet’s instructions are difficult,” to which Data responds, “Difficult? How so? Simply solve the mystery of Farpoint Station. Feeding these lines and their responses into the fine-tuning API builds a model that learns how to talk like Data. This illustrates the power of the new models, which can be fine-tuned using this API to train on the latest advancements.
Necessity of Fine-Tuning vs. Prompt Engineering
OpenAI emphasizes the importance of evaluating whether fine-tuning is truly necessary, as their models perform exceptionally well out of the box. Often, you can achieve desired results through prompt engineering—refining your prompts or providing a few examples—rather than resorting to the more costly and complex process of fine-tuning.
With older models, fine-tuning was more incentivized, but the newer models, like GPT-4o, often don’t require it. For instance, even GPT-3.5 can adequately play the role of Data from Star Trek without fine-tuning, although fine-tuning enhances its performance. (This capability does raise questions about how the model may have been trained on copyrighted TV scripts.)
Creating Training Data for Fine-Tuning
Once you have a fine-tuned model, it will be used with the chat completions API instead of the legacy completions API. The process is straightforward: define the message structure, omitting the assistant role to let the model generate it. You can provide both training and validation files for the fine-tuning job. Use OpenAI’s file API to upload these files in advance, referring to them by their IDs in subsequent requests to initiate the fine-tuning job. This approach provides objective metrics on the model’s performance, allowing you to assess how accurately it predicts responses, such as those Data from Star Trek might have given.
Python Script for Extracting Dialogue
Let’s explore an example of creating a real AI based on a fictional AI using OpenAI’s fine-tuning API. We aim to fine-tune GPT to simulate Data from Star Trek: The Next Generation. By training the model with every line of dialogue Data ever said, we can produce a simulation closely resembling the original character.
To gather this data, we extract every line spoken by Data and the preceding line from the scripts of Star Trek: The Next Generation. Although sharing the scripts directly would infringe copyright, they are accessible online for personal use.
The challenge is to create a training data file for fine-tuning GPT. The system role is defined as an android from Star Trek: The Next Generation, with the user being whoever interacts with Data. For example, Picard might say “You will agree, Data, that Starfleet’s instructions are difficult,”, and Data would respond, “Difficult? How so?” By doing this for all of Data’s lines, we can use the chat completions API to generate responses consistent with Data’s speech in the show.
Uploading Files and Starting the Fine-Tuning Job
To begin the fine-tuning process, we need to prepare a script. This script, named extract_script_new.py, is a pre-processing Python script designed to handle data wrangling, which is a crucial part of the job. The script starts by using the process_directory function, which points to the directory where all the Star Trek scripts are stored. If you’re replicating this process, ensure you adjust the path to match where your scripts are saved.
The script allows for the simulation of any Star Trek character, but for this project, we focus on Data, as it poetically simulates a real AI with a fictional one.
# extract_script_new.py
import os
import re
import random
character_lines = []
def strip_parentheses(s):
return re.sub(r'\(.*?\)', '', s)
def is_single_word_all_caps(s):
# First, we split the string into words
words = s.split()
# Check if the string contains only a single word
if len(words) != 1:
return False
# Make sure it isn't a line number
if bool(re.search(r'\d', words[0])):
return False
# Check if the single word is in all caps
return words[0].isupper()
def process_directory(directory_path, character_name):
for filename in os.listdir(directory_path):
file_path = os.path.join(directory_path, filename)
if os.path.isfile(file_path): # Ignore directories
extract_character_lines(file_path, character_name)
with open(f'./{character_name}_lines.jsonl', 'w', newline='') as outfile:
prevLine = ''
for s in character_lines:
if (s.startswith('DATA:')):
outfile.write("{\"messages\": [{\"role\": \"system\", \"content\": \"Data is an android in the TV series Star Trek: The Next Generation.\"}, {\"role\": \"user\", \"content\": \"" + prevLine + "\"}, {\"role\": \"assistant\", \"content\": \"" + s + "\"}]}\n")
prevLine = s
def extract_character_lines(file_path, character_name):
with open(file_path, 'r') as script_file:
lines = script_file.readlines()
is_character_line = False
current_line = ''
current_character = ''
for line in lines:
strippedLine = line.strip()
if (is_single_word_all_caps(strippedLine)):
is_character_line = True
current_character = strippedLine
elif (line.strip() == '') and is_character_line:
is_character_line = False
dialog_line = strip_parentheses(current_line).strip()
dialog_line = dialog_line.replace('"', "'")
character_lines.append(current_character + ": " + dialog_line)
current_line = ''
elif is_character_line:
current_line += line.strip() + ' '
def split_file(input_filename, train_filename, eval_filename, split_ratio=0.8, max_lines=10000):
"""
Splits the lines of the input file into training and evaluation files.
:param input_filename: Name of the input file to be split.
:param train_filename: Name of the output training file.
:param eval_filename: Name of the output evaluation file.
:param split_ratio: Ratio of lines to be allocated to training. Default is 0.8, i.e., 80%.
"""
with open(input_filename, 'r') as infile:
lines = infile.readlines()
# Shuffle lines to ensure randomness
random.shuffle(lines)
lines = lines[:max_lines]
# Calculate the number of lines for training
train_len = int(split_ratio * len(lines))
# Split the lines
train_lines = lines[:train_len]
eval_lines = lines[train_len:]
# Write to the respective files
with open(train_filename, 'w') as trainfile:
trainfile.writelines(train_lines)
with open(eval_filename, 'w') as evalfile:
evalfile.writelines(eval_lines)
process_directory('e:/Downloads23/scripts_tng', 'DATA')
split_file('./DATA_lines.jsonl', './DATA_train.jsonl', './DATA_eval.jsonl')
The process_directory function iterates through each file in the specified directory, confirming each is a file and not a directory. It then passes the file to the extract_character_lines function. Since scripts are not structured data, assumptions are made to process the information. The script reads each line into an array called lines and tracks whether the current line is part of a dialogue.
The assumption is that a line with a single word in all caps, without numbers, indicates a character’s dialogue. For example, if “PICARD” is in all caps, the following lines are assumed to be Picard’s dialogue. A blank line indicates the end of the dialogue.
The script identifies who is speaking by looking for these capitalized words, using the is_single_word_all_caps function to confirm character names. The output is written to data_lines.jsonl, formatted for the chat completions API. Each line includes a system role, which provides context that Data is an android in “Star Trek: The Next Generation,” a user role for the person speaking to Data, and an assistant role for Data’s response.
Finally, the script creates training and evaluation files, allowing OpenAI to measure the model’s progress. This process helps determine how accurately the model simulates Data’s speech, providing metrics to evaluate its performance objectively.
Monitoring the Fine-Tuning Process
To prepare for fine-tuning, we use a function to split the original data_lines.jsonl file into data_train and data_eval files, following an 80-20 split for training and testing data. This split ensures that the model has sufficient data for training while reserving a portion for evaluation.
For cost efficiency during development, you can limit the number of lines processed by setting max_lines to a smaller number. Initially, I used 100 lines of Data’s dialogue to expedite the process and minimize costs. However, the complete dataset contains approximately 6,000 lines, and for this example, we increase it to 10,000 lines to ensure comprehensive training.
To generate these files, execute the command python extract-script-new.py. This script will create the necessary training and evaluation files, readying them for use in fine-tuning the model.
Comparing Fine-Tuned and Non-Fine-Tuned Models
To evaluate the effectiveness of the fine-tuning process, we can use a Jupyter notebook to run comparisons between the fine-tuned and non-fine-tuned models. This step involves executing the fine-tuning process and analyzing the results. Note that fine-tuning can incur costs, potentially around $50, so consider this before proceeding with your own experiments.
!pip install openai --upgrade
Output:
Requirement already satisfied: openai in e:\anaconda3\lib\site-packages (0.27.9) Requirement already satisfied: tqdm in e:\anaconda3\lib\site-packages (from openai) (4.64.1) Requirement already satisfied: requests>=2.20 in e:\anaconda3\lib\site-packages (from openai) (2.28.1) Requirement already satisfied: aiohttp in e:\anaconda3\lib\site-packages (from openai) (3.8.3) Requirement already satisfied: idna<4,>=2.5 in e:\anaconda3\lib\site-packages (from requests>=2.20->openai) (3.4) Requirement already satisfied: certifi>=2017.4.17 in e:\anaconda3\lib\site-packages (from requests>=2.20->openai) (2022.12.7) Requirement already satisfied: urllib3<1.27,>=1.21.1 in e:\anaconda3\lib\site-packages (from requests>=2.20->openai) (1.26.13) Requirement already satisfied: charset-normalizer<3,>=2 in e:\anaconda3\lib\site-packages (from requests>=2.20->openai) (2.1.1) Requirement already satisfied: frozenlist>=1.1.1 in e:\anaconda3\lib\site-packages (from aiohttp->openai) (1.3.3) Requirement already satisfied: aiosignal>=1.1.2 in e:\anaconda3\lib\site-packages (from aiohttp->openai) (1.3.1) Requirement already satisfied: multidict<7.0,>=4.5 in e:\anaconda3\lib\site-packages (from aiohttp->openai) (6.0.2) Requirement already satisfied: async-timeout<5.0,>=4.0.0a3 in e:\anaconda3\lib\site-packages (from aiohttp->openai) (4.0.2) Requirement already satisfied: attrs>=17.3.0 in e:\anaconda3\lib\site-packages (from aiohttp->openai) (22.1.0) Requirement already satisfied: yarl<2.0,>=1.0 in e:\anaconda3\lib\site-packages (from aiohttp->openai) (1.8.1) Requirement already satisfied: colorama in e:\anaconda3\lib\site-packages (from tqdm->openai) (0.4.6)
To begin, ensure you have the latest version of the OpenAI package installed, as version 27.9 or later is required for the fine-tuning API. After installation, import the necessary os and OpenAI packages. Set your API key using your OpenAI developer key, which should be stored in a system variable, such as openai_api_key. This key is essential for accessing the API, but once set, you won’t need to reference it again, simplifying the process.
import os from openai import OpenAI client = OpenAI()
To begin the fine-tuning process, upload the training and evaluation data files using the OpenAI file API. Specify the file path and set the purpose to ‘fine-tune’ to ensure proper usage. After uploading, the API will return file IDs, which are necessary for subsequent requests.
To ensure your files are ready for fine-tuning, it’s important to check their status. This step will reveal any validation errors, such as malformed JSON. You can use the file.retrieve method with the file ID to verify the status. For instance, when checking an evaluation file, it should confirm that everything is fine. If there are issues, it will indicate errors and guide you on how to fix them. OpenAI plans to release a Python script to help validate data and estimate training costs, which may be available by the time you read this.
With our training and evaluation data ready, we can initiate the fine-tuning job. To do this, we pass the ID of the training file uploaded via the file API, along with the optional validation file, and specify the model we wish to fine-tune, which in this case is GPT-3.5-turbo but should also work with newer models. This process allows us to customize GPT to meet specific needs, such as simulating Data from Star Trek.
Once the fine-tuning job is initiated, it provides information about the job status. Monitoring the progress is important, as the process can take some time; in this case, it took about half an hour, which is quite efficient. To track the job, use the fine-tuning job.retrieve function with the job ID provided in the response to the create call. This function gives general information about the fine-tuning job, ensuring it is proceeding correctly.
For instance, the default number of epochs is set to three, but you can specify a different number if needed. Keep in mind that costs are incurred per epoch based on the number of tokens in your training dataset. Therefore, it’s advisable not to exceed the necessary number of epochs unless you’re prepared for the additional expense.
To monitor the progress of your fine-tuning job, you can use the list_events function. This allows you to specify which events you want to track and how many of the most recent events you wish to see. By passing in the ID of your fine-tuning job, you can receive updates on its status. Once the job is complete, you’ll receive a message confirming its success, along with the ID of the fine-tuned model. This ID is crucial for using the model with the chat completions API or in the playground.
Upon completion, the training loss was recorded at 1.89, and the token accuracy was 0.54. Unlike previous experiments where metrics were provided throughout the training process, this time only the final metrics were available. Typically, you would see these metrics fluctuate as training progresses, providing insight into the model’s improvement.
Conclusion: The Future of AI Development
In this article, we explored the fascinating process of fine-tuning GPT to create a real AI version of Star Trek’s Data. We explored the intricacies of OpenAI’s fine-tuning API, the preparation of training data, and the steps involved in customizing an AI model. This experiment not only showcased the practical applications of advanced AI technologies but also highlighted the intersection between science fiction and real-world artificial intelligence. By understanding these processes, we gain valuable insights into the potential and limitations of current AI development techniques. Thank you for joining us on this journey through the cutting edge of AI technology.
If you’re intrigued by the possibilities of AI and machine learning, and want to dive deeper into these topics, consider exploring the comprehensive Machine Learning, Data Science and Generative AI with Python course. This course covers a wide range of topics from basic statistics to advanced AI techniques, providing you with the skills needed to excel in the rapidly evolving field of artificial intelligence.
These are very different exams; AI Practitioner is mainly simple “which service does this” questions, while the Machine Learning Engineer exam is much more advanced – it’s basically the Machine Learning Specialty exam, but with less of a focus on system design and with an even broader scope that covers newer services like Bedrock and newer features in SageMaker.
Our prep courses reflect this; our AI Practitioner course clocks in at under 10 hours, while Machine Learning Engineer is over 22 hours! For the latter, I’ve teamed up again with celebrity instructor Stephane Maarek to pair his deep AWS service-level expertise with my own machine learning expertise.
Both are available exclusively on Udemy; please follow the links above to learn more! As always, thank you for having me along on your learning journey.
We’ve had a few outages these past few days, so just wanted to say (1) I’m sorry if you were affected by them, and more importantly, (2) I’ve addressed the underlying issue.
I’ve doubled the capacity of our underlying server, as it was just running out of memory. We’ve been seeing a lot more traffic lately, and it just couldn’t handle it. A good problem to have, I suppose!
Let’s turn this into an educational moment though, because that is what I do 🙂
Although I teach complex system designs and the use of web services, a site like this can often make do with a single monolithic server. Our current level of traffic doesn’t require anything more, and you should always opt for the simplest solution that meets your needs. This site runs on an Amazon Lightsail instance, running WordPress with Bitnami. The issue wasn’t with that architectural choice, it was just in choosing an instance type that didn’t keep up with our growth in an attempt to minimize costs.
But, I have automated alerts set up when the site becomes unresponsive – so as long as it happens while I’m awake, I can respond quickly. And I have automated snapshots of the site stored daily, so recovering from a hardware failure or something can be done quickly.
In this case, a few brief outages that fixed themselves after a few minutes were a warning sign I should have paid more attention to. I assumed it was some transient hacking attempt that was quickly thwarted by the security software this site runs. But a couple of days ago, the site went down, and stayed down. When I saw the alert, I examined the apache error logs which plainly pointed to PHP running out of memory. The memory limit in php.ini didn’t appear to be the problem, but running “top” on the server showed that free memory on our virtual machine was perilously low. A simple reboot freed up some resources, and bought me some time to pursue a longer-term solution.
Fortunately, in Lightsail it’s pretty easy to upgrade a server. I just restored our most recent snapshot to a new, larger instance type, and switched over our DNS entry. Done.
There are still a couple of larger instance types to choose from before we need to think about a more complex architecture, but if that day does come, Lightsail does offer a scheme for using a load balancer in front of multiple servers. We’d have to move off our underlying database to something centralized at the same time, but that’s not that hard either.
Sometimes it seems like the tech industry lives in an alternate universe. Despite headlines about how great the economy is doing and how many jobs are being added to it, the tech industry continues to undergo wave after wave of layoffs – mainly driven by investors demanding profitability by any means. A lot of smart, driven, talented people are finding themselves without a job, and it’s hard to imagine a more stressful situation to be in.
If you’re one of those people, I want to help. The most important thing in a job search these days is who you know. I don’t know if my own network on LinkedIn might expose you to new connections, but feel free to connect with my own network there. I’m also in some discussions with recruiting firms who are interested in tapping into my network of past students, as you have skills that are still in demand. More on that as things solidify.
Upskilling and interview preparation are of course important. Here are some courses that might prove especially helpful:
If you are affected by the ongoing wave of tech layoffs, I wish you prosperity and finding a new employer that’s better than the one you left – or maybe this will lead to your own endeavors taking off. Make the best use of the time you have!
The AWS Certified Data Engineer Associate Exam is one of the most challenging associate-level certification exams you can take from Amazon, and even among the most challenging overall.
Passing it tells employers in no uncertain terms that your knowledge of data pipelines is wide and deep. But, even experienced technologists need to prepare heavily for this exam.
This course will set you up for success, by covering all of the data ingestion, transformation, and orchestration technologies on the exam and how they fit together.
Enroll today for just $9.99 and save with our launch sale!
For this course, I’ve teamed up with a fellow best-selling Udemy instructor, Stéphane Maarek to deliver the most comprehensive and hands-on prep course we’ve seen. Together, we’ve taught over 2 million people around the world.
This course combines Stéphane’s depth on AWS with Frank’s experience in wrangling massive data sets, gleaned during his 9-year career at Amazon itself.
Throughout the course, you’ll have lots of opportunities to reinforce your learning with hands-on exercises and quizzes. We’ll also arm you with some valuable test-taking tips and strategies along the way.
Although this is an associate-level exam, it is one of the more challenging ones. AWS recommends having a few years of both data engineering experience and AWS experience before tackling it. This exam is not intended for AWS beginners.
You want to go into the AWS Certified Data Engineer Associate Exam with confidence, and that’s what this course delivers. Sign up today– we’re excited to see you in the course…and ultimately to see you get your certification!
Communication skills are important to employers. It may not jive with your ideas about meritocracy, but the reality is the world cares about more than just your coding skills.
It takes more than coding skills to be successful in business, you have to play nice with others and be an active part of a team. You have to be able to collaborate with people and communicate your ideas effectively, not only to other engineers but also to your manager and people who are outside of your discipline entirely.
So if you’re light on technical skills, learning to effectively communicate with your team could become your unique advantage.
Communication in Interviews
Let’s start with the interview, where it all begins. Your ability to communicate plays a large role in how your interviews go. So if you’re just sitting there looking depressed and mumbling and people can’t understand what you’re saying, and you can’t convey your thoughts and talk about how you’re thinking through the problems you’re being asked, that interview is not going to go well no matter how smart you are.
But if you can sit there and effectively convey what you’re thinking, your thought process, where you’re going as you’re answering these questions and do that in an articulate manner, people will say, “Hey, I like this person. I want to work with this person. This person can work well in a larger organization.” That’s important too.
How you present yourself in interviews is going to make a big difference. How you communicate on the job impacts your career in the long term. You need to be able to express your ideas clearly to other engineers and your management. It’s a hard thing to teach, but practice does help.
Find Speaking Opportunities
One way to start practicing your communication skills is through public speaking. Looking for opportunities to speak publicly even if it’s not technical related. Join local clubs and give presentations to them. I hone my skills by hosting meetings for my local astronomy club, and I’ve also worked as a DJ on the side.
Thankfully, I was born with a voice that’s okay to listen to. That is sort of an unfair advantage that I had, but it took practice for me to become a good public speaker because, as you might be, I’m a pretty hardcore introvert. I get a lot of stage fright.
It’s hard for me to get in front of a group and sound confident, but that comes with practice. Find opportunities to speak in front of a group. It doesn’t have to be in person, but just getting in front of a microphone and talking about stuff for a while will help you hone your communication skills and minimize your use of filler words.
So practice, practice, practice. Communication is important.
Communication Essentials
Next is learning the communication essentials. These include: Speaking clearly, enunciating, and making sure that you’re pronouncing all of your consonants and syllables.
Move your mouth more. Don’t just mumble. Don’t just keep your jaw locked and just move your lips. You want to move your jaw as well. The more mouth movement, the more clarity you have as you’re speaking.
Use proper grammar, especially when you’re dealing with management. A lot of people these days do most of their communication via text and the grammar there is pretty fast and loose. But in a professional setting, you might be dealing with people from an older generation, and that’s not going to fly. So do learn how to communicate using proper English grammar.
Take a course on that if you need to. If you’re not a native English speaker, that can be especially challenging. However, it is important to use complete sentences and complete grammar.
When you’re communicating in written form with management, be concise, and don’t blather on about the same thing over and over again. Get to the point. People in business don’t have a lot of time. They appreciate people who can be direct, and say, “Hey, this is the problem, this is how we’re going to fix it. What do you think?”
Don’t mince words. Avoid filler words. The ums, the ahs, and the filler words can be distracting. The more you can learn to eliminate that, the better. Try to get that filter between your brain and your mouth working as efficiently as possible.
Avoiding Jargon
Next, work to avoid using jargon when you’re talking to people who are not engineers, if you’re talking to management, artists, designers, program directors, or project managers, you can’t get into the nitty-gritty of how your code works with them.
There is a learned skill in communicating complex technical concepts to people who are not technical. Maybe you could do an online course about some sort of technology. It just takes practice. It’s a learned skill.
The more you can communicate with people outside of your discipline, the more that will open up more career paths for you going forward. And it makes it easier to communicate with people in your interview loop when you’re looking for a job because not everybody who’s interviewing you is going to be a fellow engineer. You’re going to be interviewing with your manager, you’re going to be interviewing with someone outside the team (potentially) who’s evaluating you on soft skills. You might be talking to a project manager who works with your team, so you need to learn how to communicate with people who are not engineers.
As I said, the best way to hone your communication skills is to communicate more. Join a local club, do some public speaking, give talks online, whatever it is, the more you’re in front of a microphone, a camera talking to people, or in front of a live audience, the better you’re going to get at this.
So here are the key takeaways:
Communication is essential.
Use proper grammar in professional settings.
Avoid using technical jargon with non-technical people.
This article is an excerpt from our “Mastering the System Design Interview” course. For this section, we will take a deeper dive into how to prepare for your technical interview.
What are technical hiring managers looking for? It’s more than just your technical skills, they are looking for perseverance and self-motivation. Additionally, you should be researching the companies you want to work for and prepare for your interview by practicing coding, preparing questions, and thinking big!
1. Hiring Managers are looking for perseverance and self-motivation.
Hiring managers want to see evidence of independent thought. Can you research solutions to new problems on your own? Can you invent things? Can you come up with new, novel solutions to new problems that nobody’s ever seen before?
Can you learn things independently? There is nothing more annoying than a new hire who demands help on everything that they’re asked to do when they could just look it up on the internet. Have some evidence of where you were faced with new technology and you just dove in and learned how to do it, and how you applied that knowledge to build something.
Do you have the grit to see challenging problems through to completion? They would love to hear stories about how you were faced with learning a new technology and solving a new problem.
Also, interviewers will be looking for evidence that you are self-motivated. If you don’t have specific instructions for what to do today, you should be asking your project manager or your manager, “What should I be doing today?” And if they don’t have an answer, then you should come up with something new to do on your own that will bring value to the company.
Experiment with some new idea you have, make it happen, and see how it performs. Those are great stories to have: stories of pure initiative, where you had an idea of your own, and in your own spare time, you made a prototype and experimented with it to see how it worked.
Hiring managers love that sort of thing.
2. Understand the company’s values and principles before the interview.
Big tech companies take their values seriously. They will evaluate you on how well you might embody those values. This is your cheat sheet of what sorts of stories you should have ready to tell. Demonstrate that you understand those values and that you embody them. Have stories ready to prove that to your interviewer.
They are not just looking for your technical skills, they want to make sure that you embody the company’s values. That is just as important. I’ve very often hired someone who didn’t do so well on the technical side of things, but really, really aligned well with the company’s values. And they ended up as good hires.
3. Practice coding, be well rested, prepare questions, and think big before your interview.
Practice coding and designing at the whiteboard or some virtual whiteboard, ahead of time. Writing code on a whiteboard is much harder, and it takes practice. So, get some practice. Find a friend, or find a family member, and just make them watch you while you solve technical problems on the board to make sure that you’re not thrown off kilter just by the stress of being asked to do this while somebody is watching.
If you had to fly out for an in-person interview, halfway across the world, don’t put yourself in a situation where you’re fighting jet lag at the same point where you’re trying to go through the most grueling, mentally challenging experience of your life.
Think about your questions for them ahead of time. Usually, an interview will end with, “do you have any questions for me?” And if you just say, “Nope, can’t think of anything”, you just blew an opportunity to make a good last impression on that interviewer. So, display some curiosity. Think about some questions ahead of time that you might want to ask.
Another tip is always to think big. If you’re interviewing at a big technical company, everything you do has to be on a massive scale, with massive amounts of data, and huge requirements. Make sure you’re thinking about the business and not just the technology.
So here are the key takeaways:
Perseverance and self-motivation are just as important as your technical skills.
Research the company and understand its values and principles.
Before your interview, practice coding, prepare questions to ask them, and think big!
If you’re interested in learning more on how to nail your next tech interview – check out our full course, Mastering the Systems Design Interview, click here.



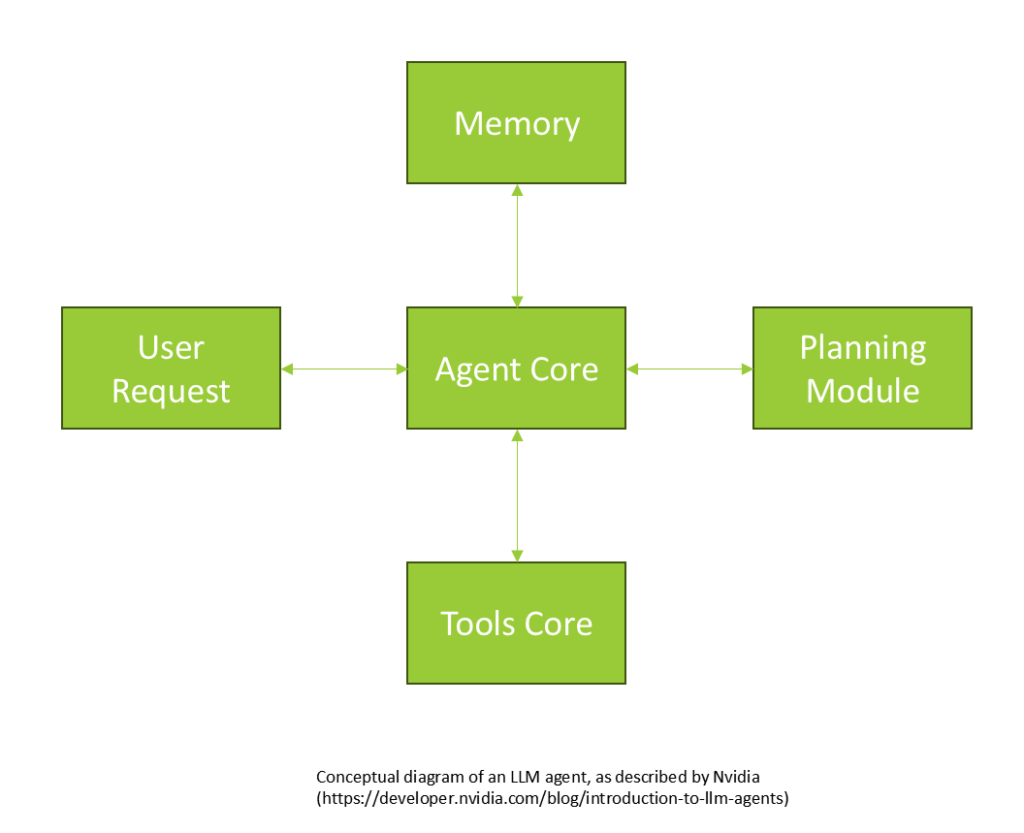
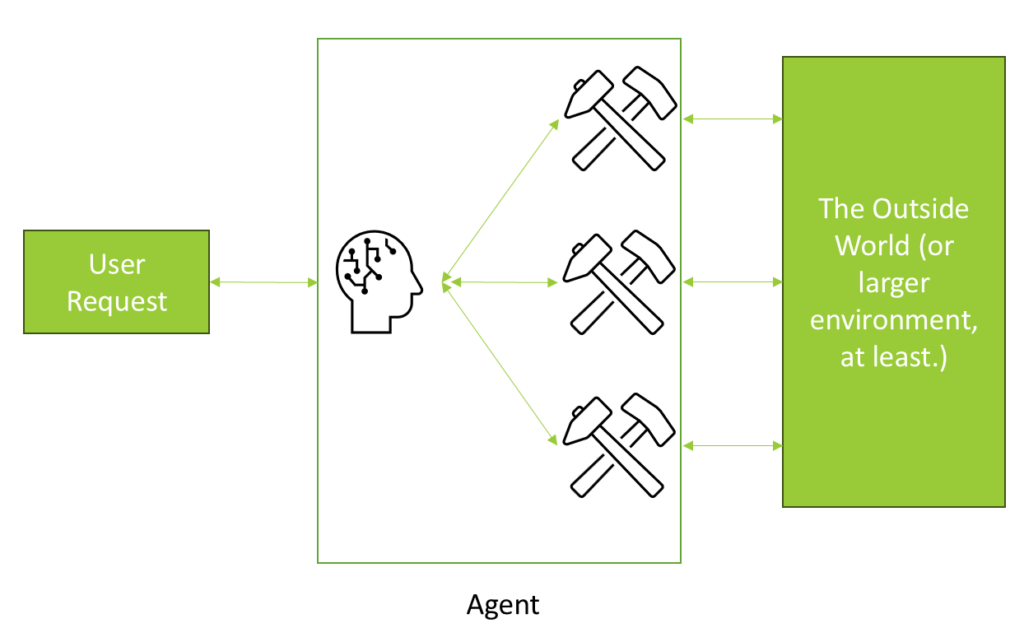
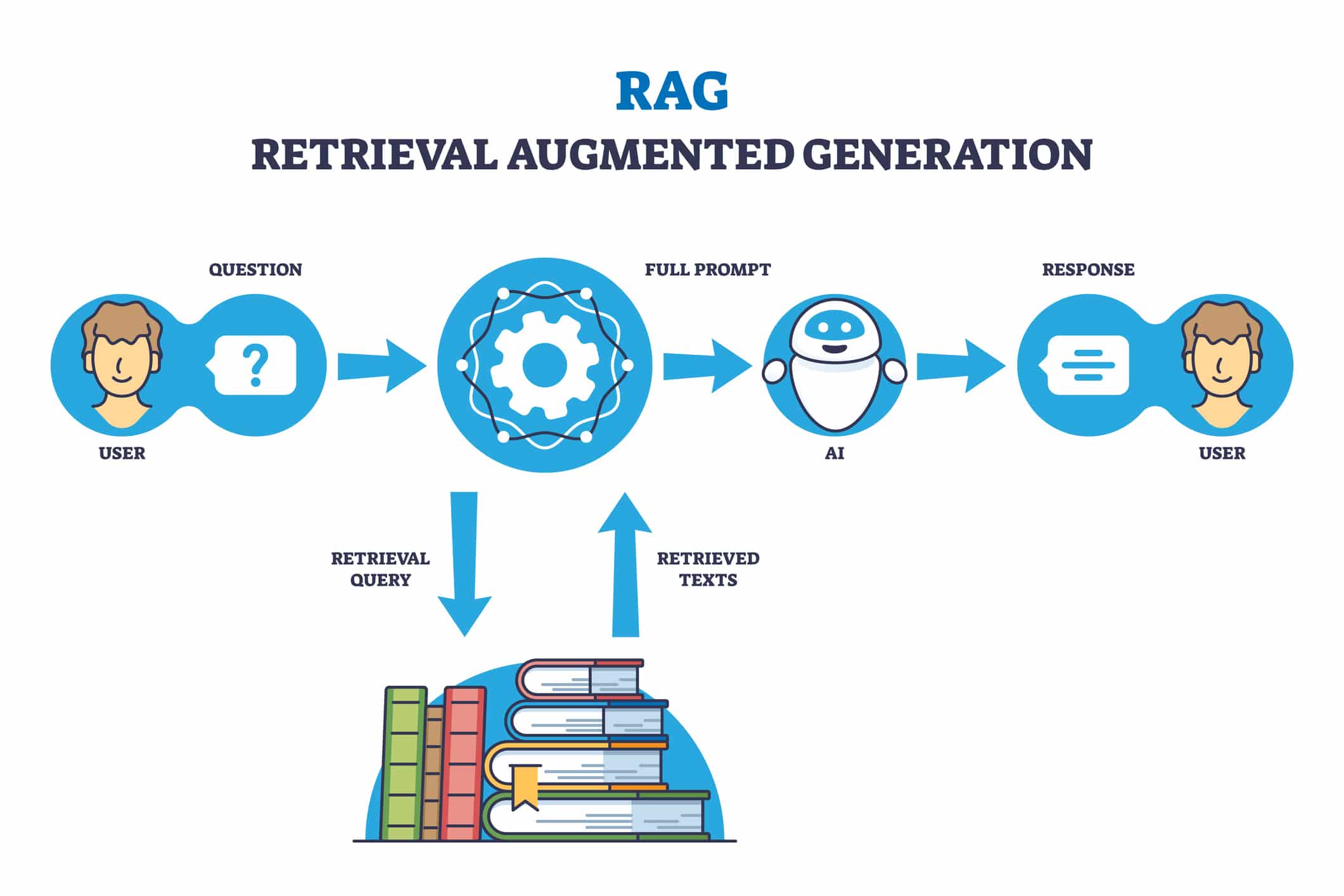

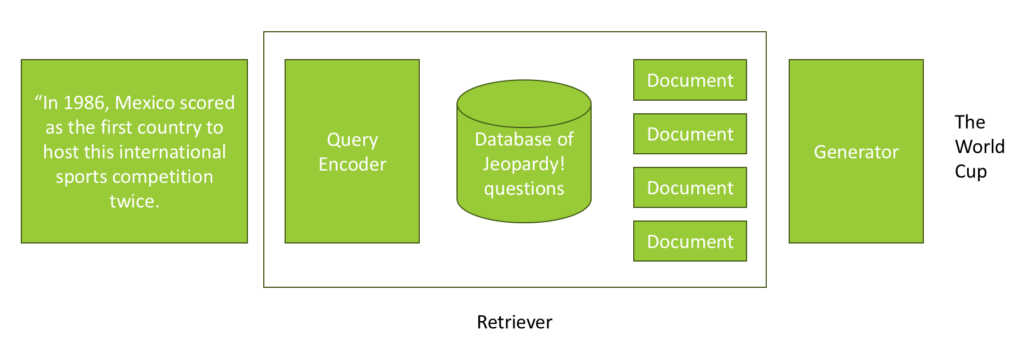
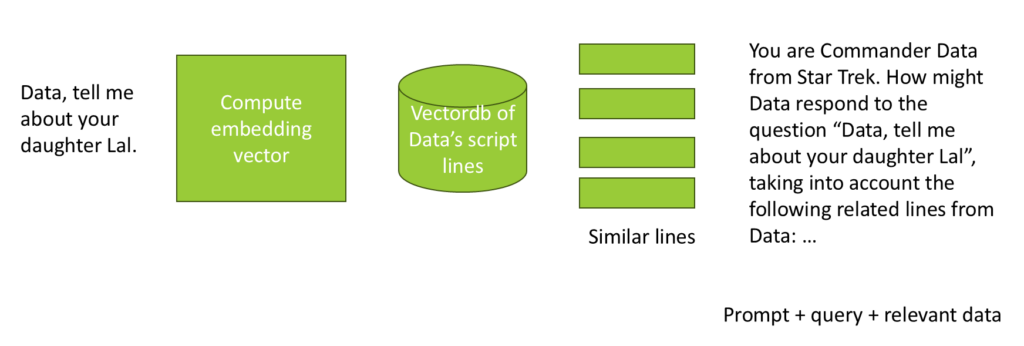








![[RETIRED] AWS Certified Machine Learning Specialty 2026](https://img-c.udemycdn.com/course/480x270/2529790_a0c6_9.jpg)


